@mrshenli, it seems you are right. It looks like a dataloading issue to me.
In DDP, with only two workers (num_workers=2), it is clear that data loading time is a bottleneck as one worker/batch is constantly taking more time to load than the other:
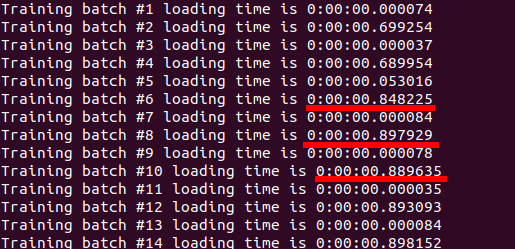
To solution is to increase the num_workers to the limit that hides the dataloading delay as in this post.
But it seems that this solution works well only with DataParallel, but not with DistributedDataParallel.
-
DataParallel num_workers=16
It is working fine because only the first batch takes 3 seconds and all consecutive batches takes almost no time
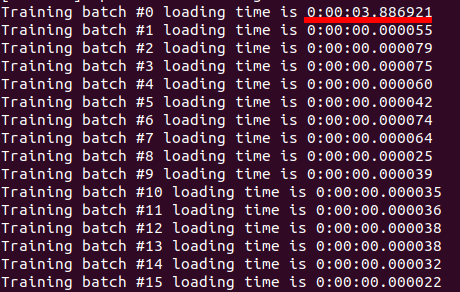
-
DistributedDataParallel num_workers=16
The first batch is taking 13 seconds to load, which is too much! and as I add more workers it takes even more.
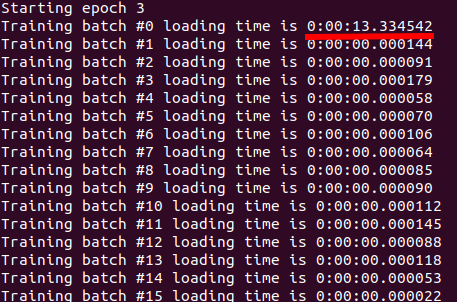
My explanation is that the data sampler is adding more overhead in DistributedDataParallel which is not the case in DataParallel.
Below again is my data sampler code to check if there is any issue with it or potential enhancement:
batch_size = 100
model = nn.parallel.DistributedDataParallel(model, device_ids=[gpu])
train_sampler = torch.utils.data.distributed.DistributedSampler(training_dataset,
num_replicas=args.world_size,
rank=rank)
training_dataloader = torch.utils.data.DataLoader(
dataset=training_dataset,
batch_size=batch_size,
shuffle=False,
num_workers=16,
sampler=train_sampler,
pin_memory=True)
I hope @VitalyFedyunin and @glaringlee can get back to us for advice about DataLoader and DataSampler.