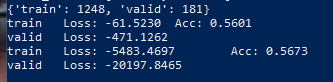
With each epochs my train loss increases and I don’t know where the error in the training code is, does anyone have any ideas?
for e in range(epochs):
# keep track of training and validation loss
train_loss = 0.0
valid_loss = 0.0
running_loss = 0.0
running_corrects = 0.0
###################
# TRAIN THE MODEL #
###################
model.train()
cont = 0
for inputs, label in (dataloaders['train']):
# IF GPU is availible
if train_on_gpu:
inputs, label = inputs.cuda(), label.cuda()
#inputs, labels = i ,data
optimizer.zero_grad()
with torch.set_grad_enabled(True):
logps = model(inputs)
_, preds = torch.max(logps, 1) # tecnica nova de validacao
loss = criterion(logps, label)
loss.backward()
optimizer.step()
#*inputs.size(0)
running_loss += loss.item()
print("running_loss = %f , interaction = %i " % (running_loss,cont) )
running_corrects += torch.sum(preds == label.data)
RL_vector.append(running_loss)
cont += 1
###################
# VALID THE MODEL #
###################
model.eval()
for inputs, label in (dataloaders['valid']):
# IF GPU is availible
if train_on_gpu:
inputs, label = inputs.cuda(), label.cuda()
with torch.no_grad():
logps = model(inputs)
_, preds = torch.max(logps, 1) # tecnica nova de validacao
loss = criterion(logps, label)
# update average validation loss
valid_loss += loss.item()
VL_vector.append(valid_loss)
# calculate average losses
epoch_loss_train = running_loss / dataset_sizes['train']
epoch_acc_train = running_corrects.double() / dataset_sizes['train']
epoch_loss_valid = valid_loss / dataset_sizes['valid']
print('{} Loss: {:.4f} \tAcc: {:.4f}'.format('train', epoch_loss_train, epoch_acc_train))
print('{} \tLoss: {:.4f} '.format('valid', epoch_loss_valid))