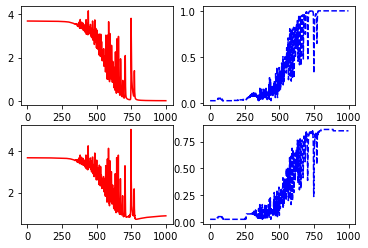
Here is my code.I dont know why my train and validation accuracy increase too slow.Is that normal? I’m new at deep learning.This is my homework
# -*- coding: utf-8 -*-
#Libraries
import torch
import torch.nn.functional as F
from torch import autograd, nn
from torch.autograd import Variable
import numpy as np
import matplotlib.pyplot as plt
from torchvision import transforms, datasets
from torch.utils import data
"""
Olivetti face dataset
"""
from sklearn.datasets import fetch_olivetti_faces
# Olivetti dataset download
olivetti = fetch_olivetti_faces()
train = olivetti.images
label = olivetti.target
X = train
Y = label
print("\nDownload Ok")
"""
Set for train
"""
train_rate = 0.8
X_train = np.zeros([int(train_rate * X.shape[0]),64,64], dtype=float)
Y_train = np.zeros([int(train_rate * X.shape[0])], dtype=int)
X_val = np.zeros([int((1-train_rate) * X.shape[0]+1),64,64], dtype=float)
Y_val = np.zeros([int((1-train_rate) * X.shape[0]+1)], dtype=int)
#Split data for train and validation
ie=0
iv=0
for i in range(X.shape[0]):
if (i%10)/9 <= train_rate:
X_train[ie] = X[i]
Y_train[ie] = Y[i]
ie += 1
else:
X_val[iv] = X[i]
Y_val[iv] = Y[i]
iv += 1
X_train = X_train.reshape(320,-1,64,64)
X_val = X_val.reshape(80,-1,64,64)
print(Y_train.shape)
X_train = torch.Tensor(X_train)
Y_train = torch.Tensor(Y_train)
X_val = torch.Tensor(X_val)
Y_val = torch.Tensor(Y_val)
batch_size = 16
train_loader = torch.utils.data.DataLoader(X_train,
batch_size=batch_size,
)
val_loader = torch.utils.data.DataLoader(X_val,
batch_size=batch_size,
)
class CNNModule(nn.Module):
def __init__(self):
super(CNNModule, self).__init__()
self.conv1 = nn.Conv2d(1, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 13 * 13, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 40)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 13 * 13)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def make_train(model,dataset,n_iters,gpu):
# Organize data
X_train,Y_train,X_val,Y_val = dataset
kriter = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(),lr=0.03)
#Arrays to save loss and accuracy
tl=np.zeros(n_iters) #For train loss
ta=np.zeros(n_iters) #For train accuracy
vl=np.zeros(n_iters) #For validation loss
va=np.zeros(n_iters) #For validation accuracy
# Convert labels to long
Y_train = Y_train.long()
Y_val = Y_val.long()
# GPU control
if gpu:
X_train,Y_train = X_train.cuda(),Y_train.cuda()
X_val,Y_val = X_val.cuda(),Y_val.cuda()
model = model.cuda() # Parameters to GPU!
print("Using GPU")
else:
print("Using CPU")
# print(X_train.shape)
# print(Y_train.shape)
for i in range(n_iters):
# train forward
train_out = model.forward(X_train)
train_loss = kriter(train_out,Y_train)
# Backward and optimization
train_loss.backward()
optimizer.step()
optimizer.zero_grad()
# Compute train accuracy
train_predict = train_out.cpu().detach().argmax(dim=1)
train_accuracy = (train_predict.cpu().numpy()==Y_train.cpu().numpy()).mean()
# For validation
val_out = model.forward(X_val)
val_loss = kriter(val_out,Y_val)
# Compute validation accuracy
val_predict = val_out.cpu().detach().argmax(dim=1)
val_accuracy = (val_predict.cpu().numpy()==Y_val.cpu().numpy()).mean()
tl[i] = train_loss.cpu().detach().numpy()
ta[i] = train_accuracy
vl[i] = val_loss.cpu().detach().numpy()
va[i] = val_accuracy
# Show result each 5 loop
if i%5==0:
print("Loop --> ",i)
print("Train Loss :",train_loss.cpu().detach().numpy())
print("Train Accuracy :",train_accuracy)
print("Validation Loss :",val_loss.cpu().detach().numpy())
print("Validation Accuracy :",val_accuracy)
model = model.cpu()
#Print result
plt.subplot(2,2,1)
plt.plot(np.arange(n_iters), tl, 'r-')
plt.subplot(2,2,2)
plt.plot(np.arange(n_iters), ta, 'b--')
plt.subplot(2,2,3)
plt.plot(np.arange(n_iters), vl, 'r-')
plt.subplot(2,2,4)
plt.plot(np.arange(n_iters), va, 'b--')
dataset = X_train,Y_train,X_val,Y_val
gpu = True
gpu = gpu and torch.cuda.is_available()
model = CNNModule()
make_train(model,dataset,1000,gpu)