Hi,
In my model , some parameters’s gradient keeps as zero, which confused me a lot. Some necessary information list as below:
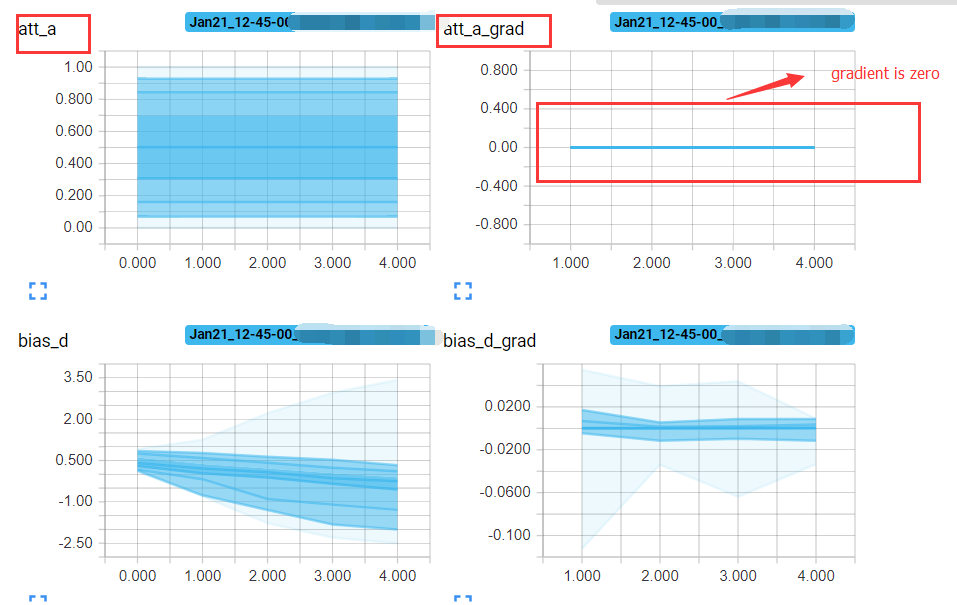
The main code about the parameters of zero-gradient:
###
some code
###
# about attention
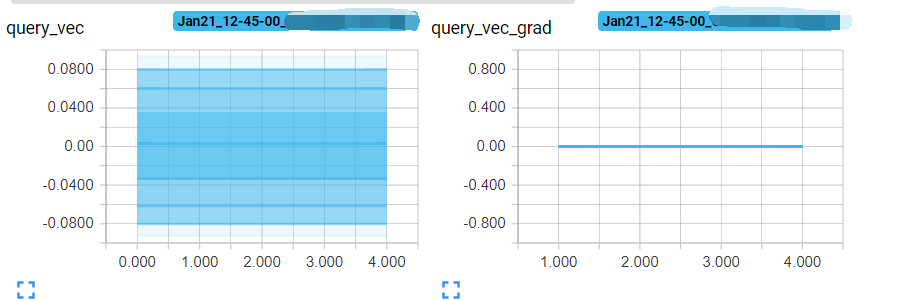
alpha = F.softmax((bag_embs * self.att_a).mm(self.query_vec), 1)
bag_embs = (bag_embs * alpha).sum(0)
batch_fea.append(bag_embs)
###
some code
###
You code sample does not show how bias_d is used so not sure how to answer.
That being said, in what you showed, if alpha is 0, then both these gradients will be 0.
I guess a good way to debug this is to print the different values during the forward to make sure they are what you expect.
Thanks for your reply. The code sample is a part of the whole model. bias_d is just a bias in one fully connected layer. And bias_d can be updated normally. But the two vectors att_a, query_vec can not be.
alpha is the attention weight , so it cannot be zero. the other parameters in the model are updated normally except for the two att-a, query_vec. It’s very strange…
Hi, I found out the problem:joy: the dim in F.softmax() should be 0 rather than 1. After changing it to 0, the gradient is normal.
Because (bag_embs * self.att_a).mm(self.query_vec) get a Variable with size K * 1 and the softmax should be applied in the first dim.
If F.softmax(..., 1), then the values in alpha are all 1.
BTW, why the gradient will become 0 when alpha is all 1.