What is the world_size in your application? Each process will have its own model replica, so the total memory consumption is expected to be larger than world_size X (non-DDP memory footprint). Besides, DDP also creates buffers for communication, which will contribute another ~1.5X if not considering optimizer.
Thanks for your answer.I set the parameter nproc_per_node to 1 and I guess the world_size is 1.There is only one process per node.However, it still consumes a lot of memory. DDP adopts the data parallelism, I think when I train this model in more nodes, there is little memory to be consumed.
I found that the node cache always uses more than 20GB of memory and if I can not reduce the memory usage,I should choose another framework to do distributed training = = !
My batch_size is 1 and datasets include 4000 samples,every sample is about 16MB.
Does this actually mean the memory is consumed by the data loader? Can you check the memory consumption when using the same model and same data loader without DDP?
I am trying to identify which component hogs memory. Could you please share some more details about the sentence below.
I have trained this model in one node and it consumed 30GB on the cache
By “trained this model in one node”, do you still use DDP and the same data loader? It will be helpful to know the memory footprint of the following cases:
Train a local model without data loader and without DDP. Just feed the model with some randomly generated tensors.
Train a local model with data loader but without DDP.
Wrap the model with DDP, and train it with data loader.
I have created a small dataset which only contains 30 samples.However the memory still decreased rapidly.(batch_size=1)
So I think this issue is not caused by dataloader and I am sure reason is the node expansion.
When I do DDP training in one node,the memory problem is not serious.When I expand the nodes,the memory problem is serious.I want to know if this is pytorch’s problem?
Could you please provide details of the following question?
Which version of PyTorch are you using?
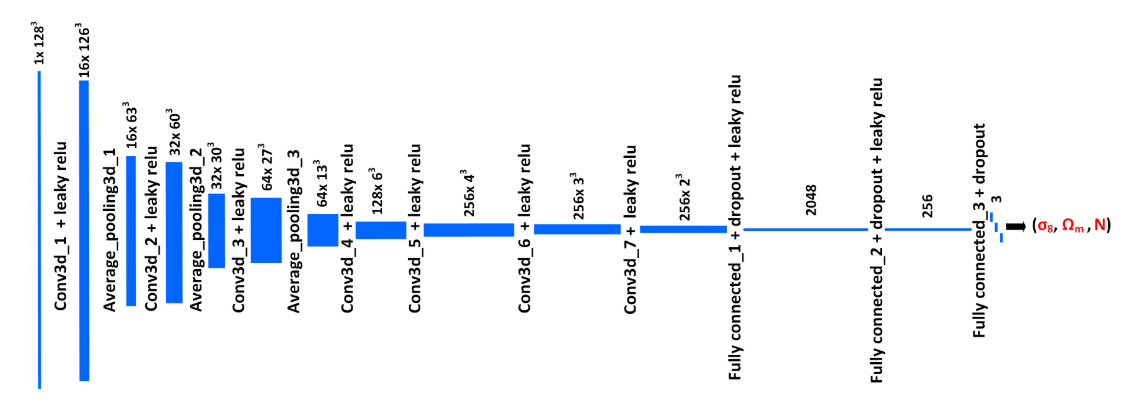
What’s the size of your model (how many GB)? You can get this by doing the following:
model_size = 0
for p in model.parameters():
model_size += p.numel() * p.element_size()
Given the picture shown in the previous post, it looks like the model is about 27GB? If that is the case, then, yes, DDP would use another 27GB as comm buffers. We are working on improving this: https://github.com/pytorch/pytorch/issues/39022
I am curious how did you train this model locally without DDP? If the model is 27GB, after the backward pass, the grads will also consume 27GB. So local training without DDP will also use >54GB memory?
And if your optimizer uses any momentum etc., it’s likely the optimizer will also consume a few more X of 27GB. But looks like there are only 64GB memory available? Is it because your optimizer does not contain any states?
Does this getting worse when you use more nodes (e.g., scale from 2 nodes to 3 nodes)?
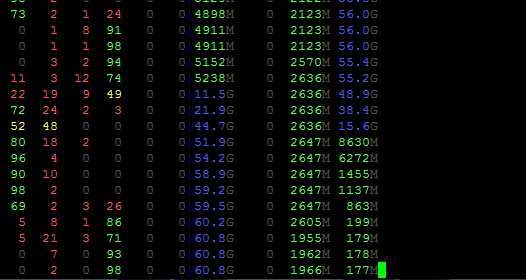
Dear @mrshenli,forgive me for not being clear,I said it consumes 30GB which means the cache
consumes 30GB.I guess the memory is used to load the disk data.I tried to use a small datasets
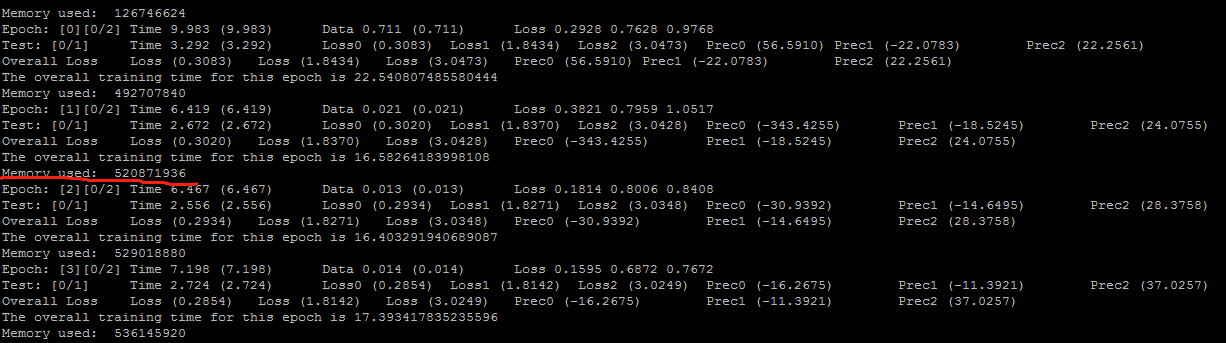
which only contains 40 samples(Every sample is 16MB).And in this case,the cache consumption is about 2.5GB.However,the memory problem still exist.You can see this picture:
Now I think the problem is not caused by dataloader.
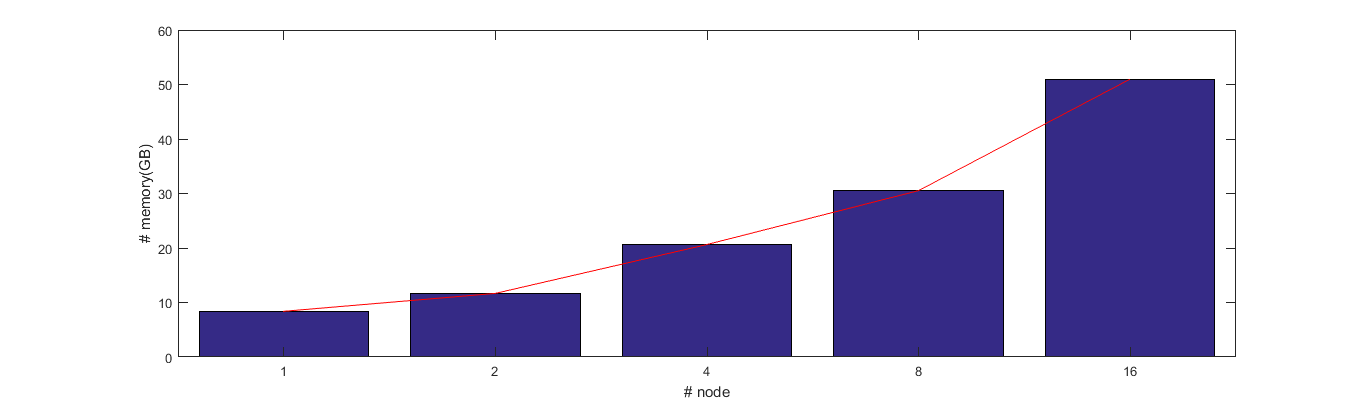
And you say DDP’s memory footprint should be constant,regardless of how many nodes are used.I test the maximum memory footprint as the nodes expand,it just like this
Thanks for the detailed information. This is weird. This is the first time that we saw the memory footprint per machine increases significantly with the total number of machines.
I guess the memory is used to load the disk data.I tried to use a small datasets
which only contains 40 samples(Every sample is 16MB).And in this case,the cache consumption is about 2.5GB.
Q1: This does not add up. The model is 10MB, and the dataset is 40X16MB = 640MB. I assume you do not use CUDA, as you mainly concerned about CPU memory. In this case, I would assume the total memory consumption to be less than 1GB. Do you know where does the other 1.5GB come from?
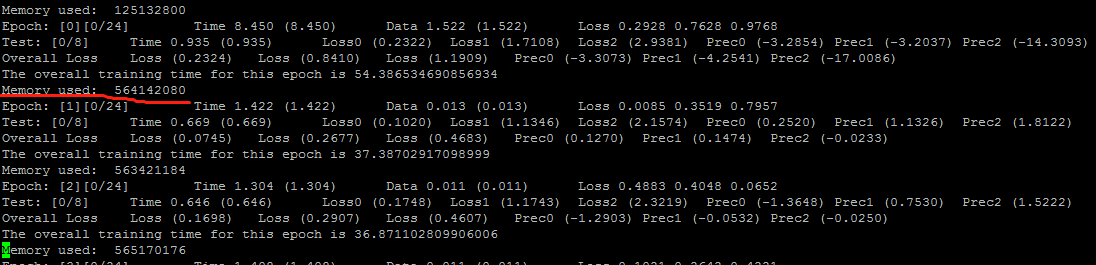
Q2: Can you try to the following to see if it is indeed used by the process instead of some os cache.
import psutil
process = psutil.Process(os.getpid())
for _ in get_batch():
....
# print this in every iteration
print("Memory used: ", process.memory_info().rss)
Q3: Do you have a minimum reprodueable example that we can investigate locally?
Q4: BTW, how do you launch your distributed training job? Are you using torch.distributed.launch. If so, could you please share the command you are using?
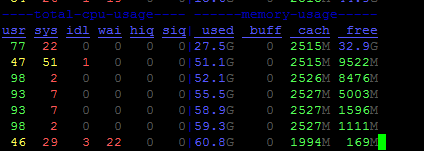
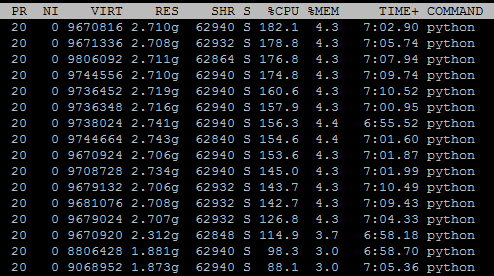
So the process memory footprint per machine does not increase with the total number of machines.However,the total memory footprint per machine increases significantly.
Then I found the process numbers increase significantly with the number of machines.
I set nproc_per_node to 1 so there should be one process in every machine.However,it is not.
There is my command:
bash.sh
....
if __name__ == '__main__':
if torch.distributed.is_available():
dist.init_process_group(backend='gloo',init_method='env://',timeout=datetime.timedelta(seconds=600))
main()
In addition,I do not use CUDA and I train this model in CPUs.
Sorry abou the delay, I have solved this problem. The reason is that I have execute the script in same node.(ssh failed) I think you can check to see if the process has started on each node.