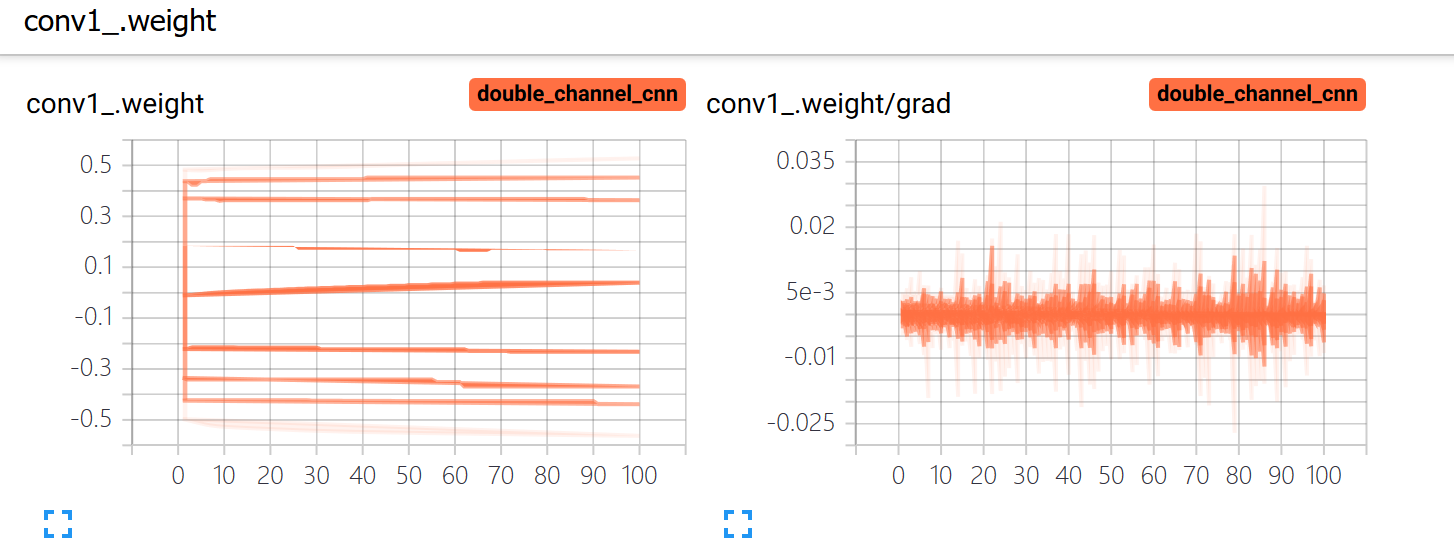
Hi, when I training my model, I find some model parameters’ grad(such as conv1.weight and conv2.weight…) is zero during the training process. Here are some code snippet:
class DC_Net(nn.Module):
def __init__(self, L):
self.L = L
super(DC_Net, self).__init__()
self.conv1 = nn.Conv2d(1, 16, 2, 2)
self.conv2 = nn.Conv1d(16, 32, (2, 1), 2)
self.conv3 = nn.Conv1d(32, 64, (2, 1), 2)
self.maxp_1 = nn.MaxPool1d(2)
self.maxp_2 = nn.MaxPool1d(2)
self.maxp_3 = nn.MaxPool1d(2)
self.conv1_ = nn.Conv2d(1, 16, 2, 2)
self.conv2_ = nn.Conv1d(16, 32, (2, 1), 2)
self.conv3_ = nn.Conv1d(32, 64, (2, 1), 2)
self.maxp_1_ = nn.MaxPool1d(2)
self.maxp_2_ = nn.MaxPool1d(2)
self.maxp_3_ = nn.MaxPool1d(2)
self.fc1 = nn.Linear(self.L, self.L-1)
self.fc2 = nn.Linear(self.L-1, 1)
self.fc1_ = nn.Linear(self.L, self.L-1)
self.fc2_ = nn.Linear(self.L-1, 1)
self.fc3 = nn.Linear(2, 1)
def forward(self, x):
out1 = self.maxp_1(F.relu(self.conv1(x)).squeeze())
out1 = self.maxp_2(F.relu(self.conv2(out1.unsqueeze(-1))).squeeze())
out1 = self.maxp_3(F.relu(self.conv3(out1.unsqueeze(-1))).squeeze())
out2 = self.maxp_1_(F.relu(self.conv1_(x)).squeeze())
out2 = self.maxp_2_(F.relu(self.conv2_(out2.unsqueeze(-1))).squeeze())
out2 = self.maxp_3_(F.relu(self.conv3_(out2.unsqueeze(-1))).squeeze())
out1 = out1.view(-1, self.L)
out2 = out2.view(-1, self.L)
out1 = F.relu(self.fc1(out1))
out2 = F.relu(self.fc1_(out2))
out1 = F.relu(self.fc2(out1))
out2 = F.relu(self.fc2_(out2))
out = torch.cat((out1, out2), 1)
w = self.fc3(out)
return w
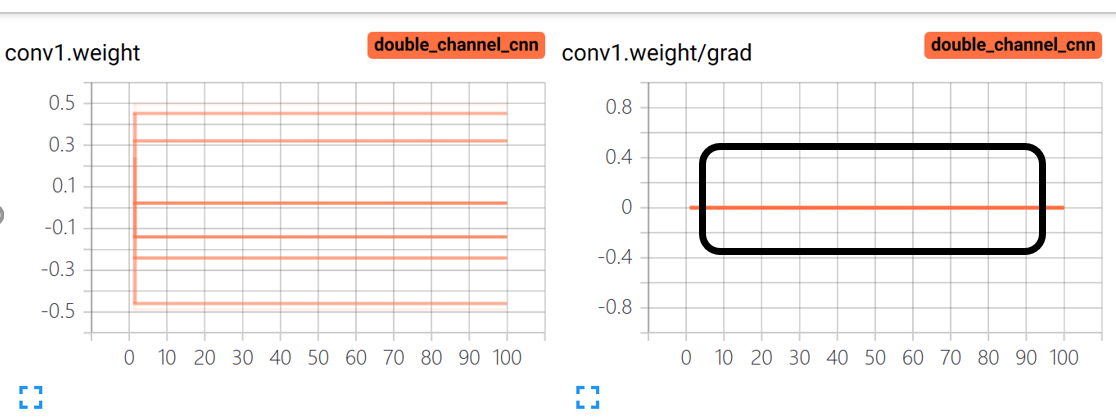
could someone tell me how to fix this problem?