The problem is located at torch.nn.MultiheadAttention module. Here is my model part code:
class CNNEncoder(nn.Module):
def __init__(self, config):
super(CNNEncoder, self).__init__()
self.embedding = config['embedding_matrix']
self.n_filters = config['model']['encoder']['num_layers']
self.embedding_dim = config['model']['embed_size']
self.filter_sizes = config['model']['encoder']['filter_size']
self.head = config['model']['encoder']['attention_heads']
self.dropout = config['model']['encoder']['dropout']
# self.dropout = nn.Dropout(0.15)
self.batch_size = config['model']['batch_size']
self.convs = nn.ModuleList([
nn.Conv2d(in_channels=1,
out_channels=self.n_filters,
kernel_size=(fs, self.embedding_dim))
for fs in self.filter_sizes
])
self.attn = nn.MultiheadAttention(embed_dim=self.n_filters * len(self.filter_sizes), num_heads=self.head, dropout=self.dropout) #embed_dim=300, num_heads=100
def forward(self, text):
# text = [batch size, sent len]
embedded = self.embedding(text)
# embedded = [batch size, sent len, emb dim]
embedded = embedded.unsqueeze(1)
# embedded = [batch size, 1, sent len, emb dim]
conved = [F.relu(conv(embedded)).squeeze(3) for conv in self.convs]
# conved_n = [batch size, n_filters, sent len - filter_sizes[n] + 1]
pooled = [F.max_pool1d(conv, conv.shape[2]).squeeze(2) for conv in conved]
# pooled_n = [batch size, n_filters]
cat = torch.cat(pooled, dim=1)
# cat = [batch size, n_filters * len(filter_sizes)]
cat = cat.view(self.batch_size, -1, self.n_filters * len(self.filter_sizes))
# cat = [batch size, 1, n_filters * len(filter_sizes)]
cat = cat.permute(1,0,2) #[1, batch size, 300]
attn_output, attn_output_weight = self.attn(query=cat, key=cat, value=cat) #k,q,v are same
return attn_output.permute(1,0,2)
class Siamese_cnn_pair(nn.Module):
def __init__(self, config):
super(Siamese_cnn_pair, self).__init__()
self.encoder = CNNEncoder(config)
self.ling_dim = config['model']['ling_feature_size']
# self.ling_embedding = config['ling_embedding_matrix']
self.dropout = nn.Dropout(config['model']['encoder']['dropout'])
self.input_dim = self.encoder.n_filters * len(self.encoder.filter_sizes)
self.fc1 = nn.Linear(self.input_dim, 128)
self.fc2 = nn.Linear(128,2)
def forward(self, a1, a2):
a = torch.cat([a1,a2], dim=1)
if torch.cuda.is_available():
a = a.cuda()
output1 = self.encoder(a).squeeze(1) # batchsize * hidden_size(*2)
output1 = self.fc1(output1)
output1 = self.fc2(output1) # batchsize * [c1, c2], binary classification.
return output1
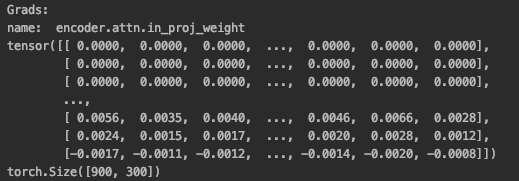
after loss.backward(), all other layer parts works normally, except encoder.attn.in_proj_weight.grad and encoder.attn.in_proj_bias.grad,
attn.in_proj_bias.grad have torch.Size([270,000]) (300 * 300 * 3(k,q,v)), but its first 180,000 are all zero, the last 90,000 have non-zero value. the situation is similar with attn.in_proj_weight.grad (torch.Size([900, 300])) it seems like only one of key, query, value matrix weight got gradient. And I don’t why it is, and how to fix it. Here is the output of attn.in_proj_weight.grad.