Since the first term of KLDivLoss[1] (the entropy of ground truth; y_true * log(y_true)) is constant, it is negligible when calculating gradients.
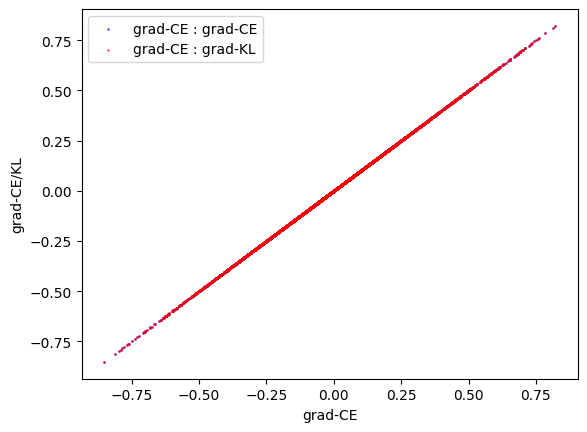
I also checked in my notebook[2] if the calculated gradient between KLDivLoss and CrossEntropyLoss is equal(Figure 1).
So, what is the use-case to calculate the entropy term of KLDivLoss? Isn’t it meaningless when computing gradient?
Figure 1: Comparison between gradient of CELoss and KLDivLoss.