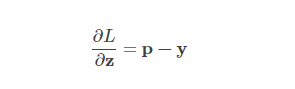Here is my code, it’s similar to official example.
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
loss = nn.CrossEntropyLoss()
feature = torch.ones(3, 5, requires_grad=True)
target = torch.empty(3, dtype=torch.long).random_(5)
output_sm = F.log_softmax(feature, dim=1)
output_nll = F.nll_loss(output_sm, target)
output = output_nll
output.backward()
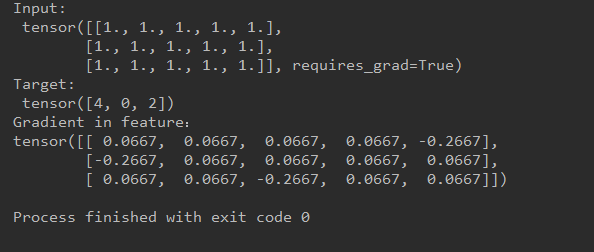
print("Input:\n", feature)
print("Target:\n", target)
print("Gradient in feature:\n", feature.grad)
The picture below is my results.
The result of theoretical deduction is as follow:
Partial derivative of L to z equals p - y
L represents loss function
z is the input feature
p is the output of softmax
y is the target
Regarding the detailed derivation of this formula, I am not here because it is easy to get.
What confused me is the experimental results do not match the theoretical values?
Can you give me some suggestion? Thank you!