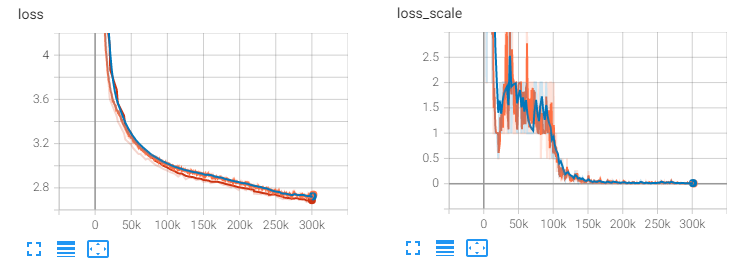
Hello, now I am pretraining a HuBERT model, I have found that when the loss getting smaller, but increasingly frequent occurrences of gradient overflow, leading to a decreasing loss_scale.
My understanding is that when the loss becomes smaller and smaller, it indicates that the model has converged. So why would gradient overflow occur more frequently?