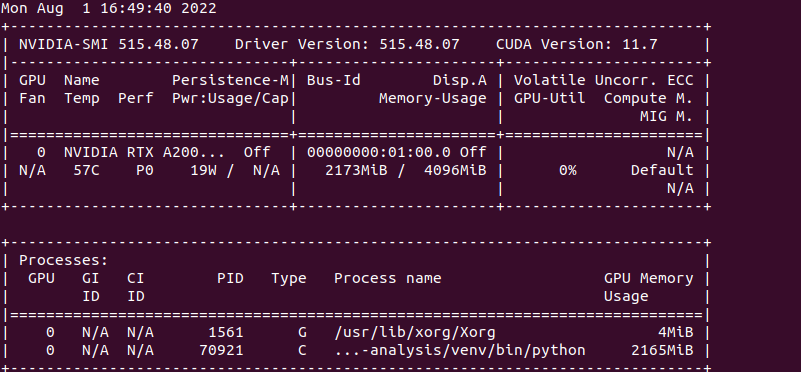
I ran nvidia-smi before running any code, and it showed only xorg with 4MiB ( can’t attach print screen because I am new in this forum)
I wrote this code in a clean jupyter notebook, with new kernel:
import torch
a = torch.randn((1), device=torch.device(“cuda”), dtype=torch.float)
After running nvidia-smi this is the result I got:
Why does this code take 2GB of memory?
I suppose it is something pytorch does when initialising, but, is there a way to reduce this?
I think there is another process that is taking the memory. Can you kill your jupyter kernel and check GPU usage?
The first CUDA operation will initialize the CUDA context, which will load the driver, all native PyTorch kernels, all kernels from linked libraries (cublas, cuDNN etc.) and will thus add this overhead.
You could reduce it by enabling CUDA’s lazy loading functionality in CUDA 11.7. For now you could manually build it from source or wait until we publish the binaries as nightly builds soon (we are already building them, but are going through some more testing).
2 Likes
Another person I asked to run the same code, showed only 500M of GPU memory for the process. Do you know what may be the difference? Why it is 4 times lower on his side?
The context size depends on the used library versions, CUDA/driver version, compute architecture, number of SMs on your GPU etc., so it won’t be constant.
1 Like