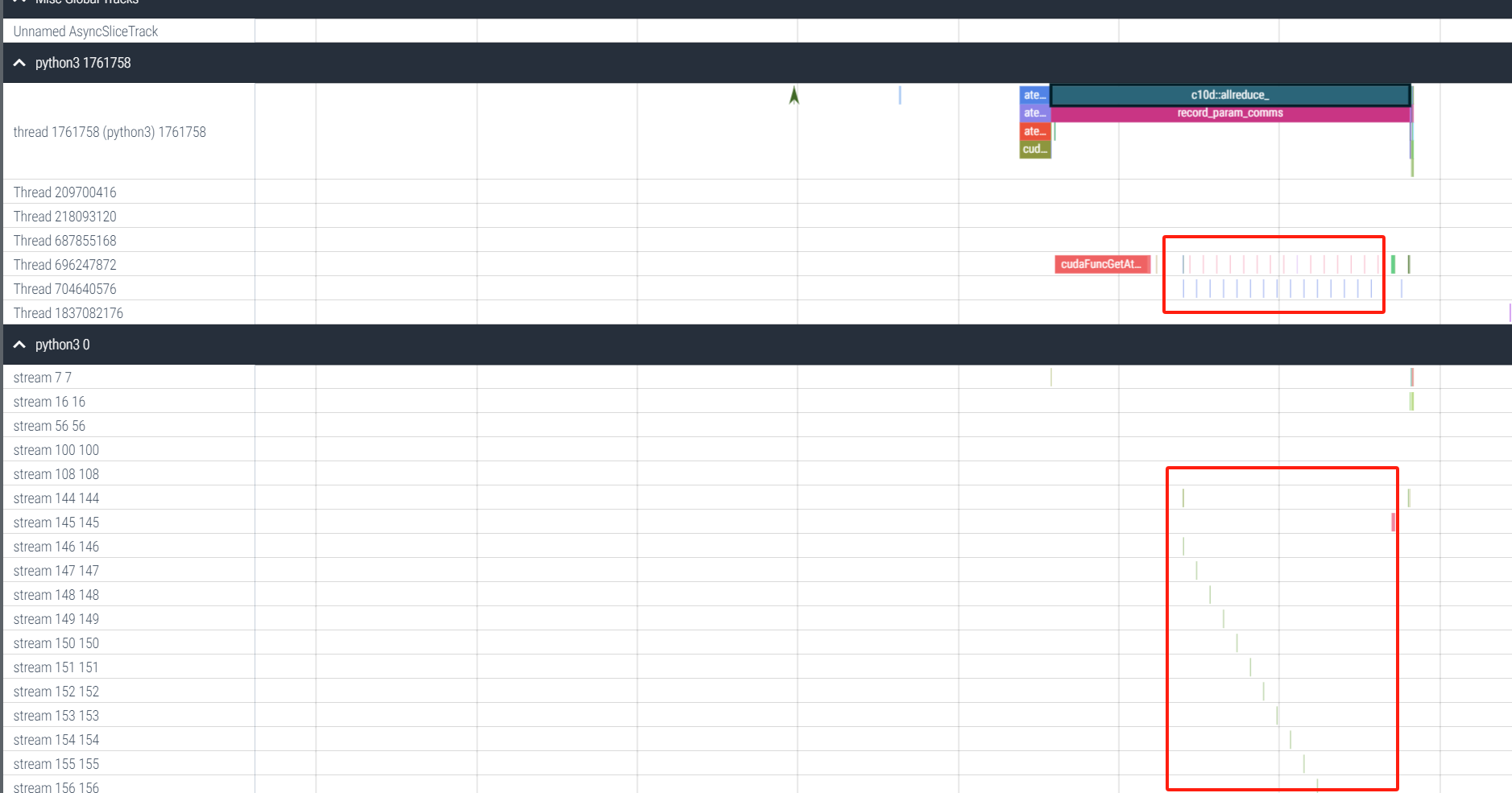
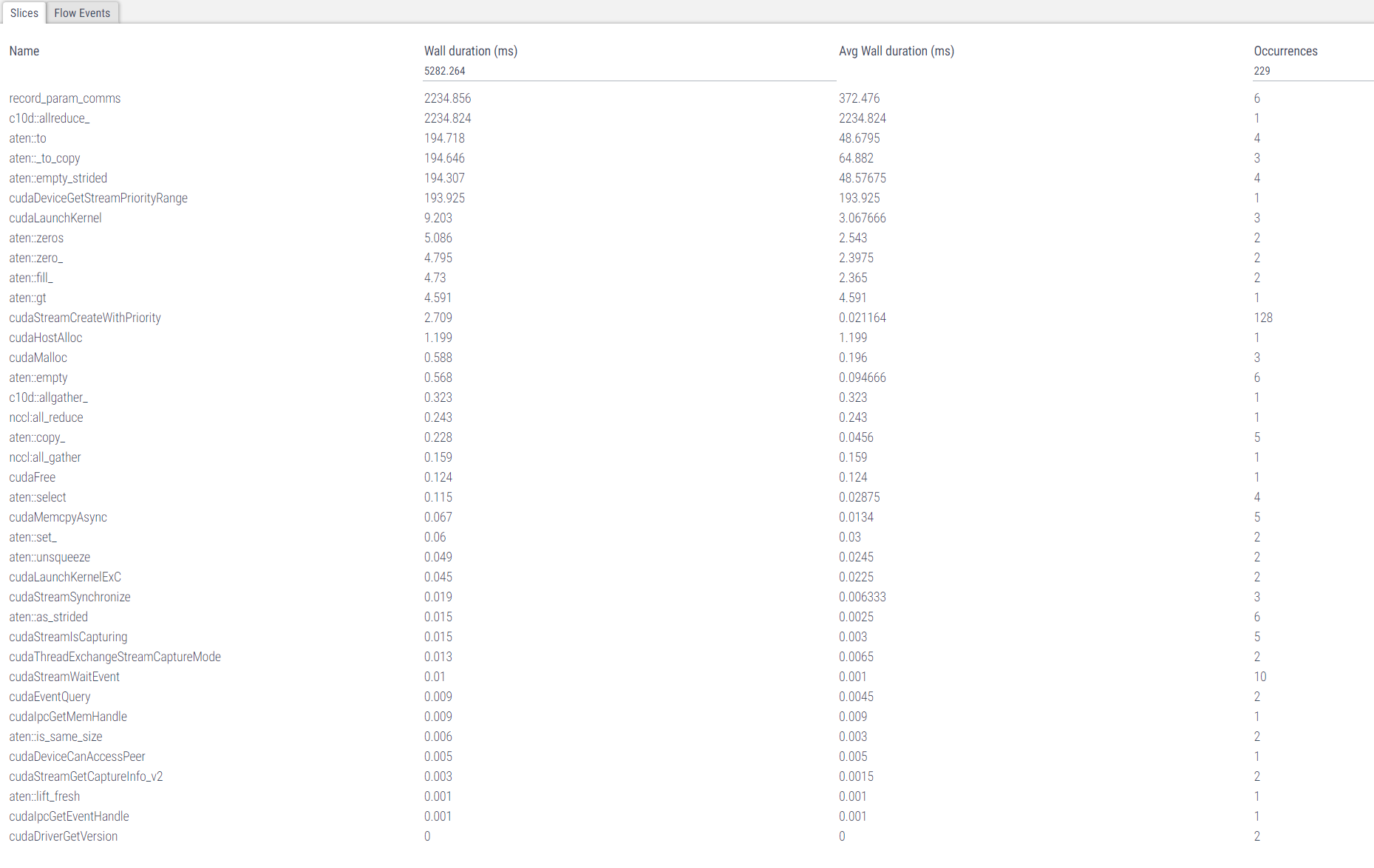
I run torch.distributed.all_reduce in my code with the nccl backend.
I find that it takes very long to finish (about 2s). Then I profile the code and find that during the all_reduce, there are a lot of memory copy operations between the device and the host.
The profiling result is shown below:
When profiling its usually common practice to take a profile after a few steps into training so setup and cache warmup do not play a factor in the traces