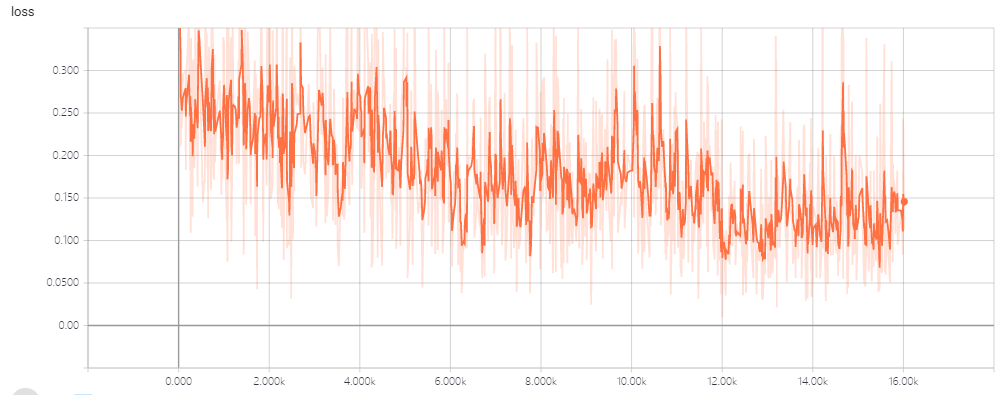
Smoothing=0.65
batch size=40
gpu num=2
learning rate = 3e-5
The model is based on bert and is used to complete simple binary classification task.
In previous experiments, I set batch size to 16, and the situation is similar.
Does anyone have a good suggestion to change this situation?