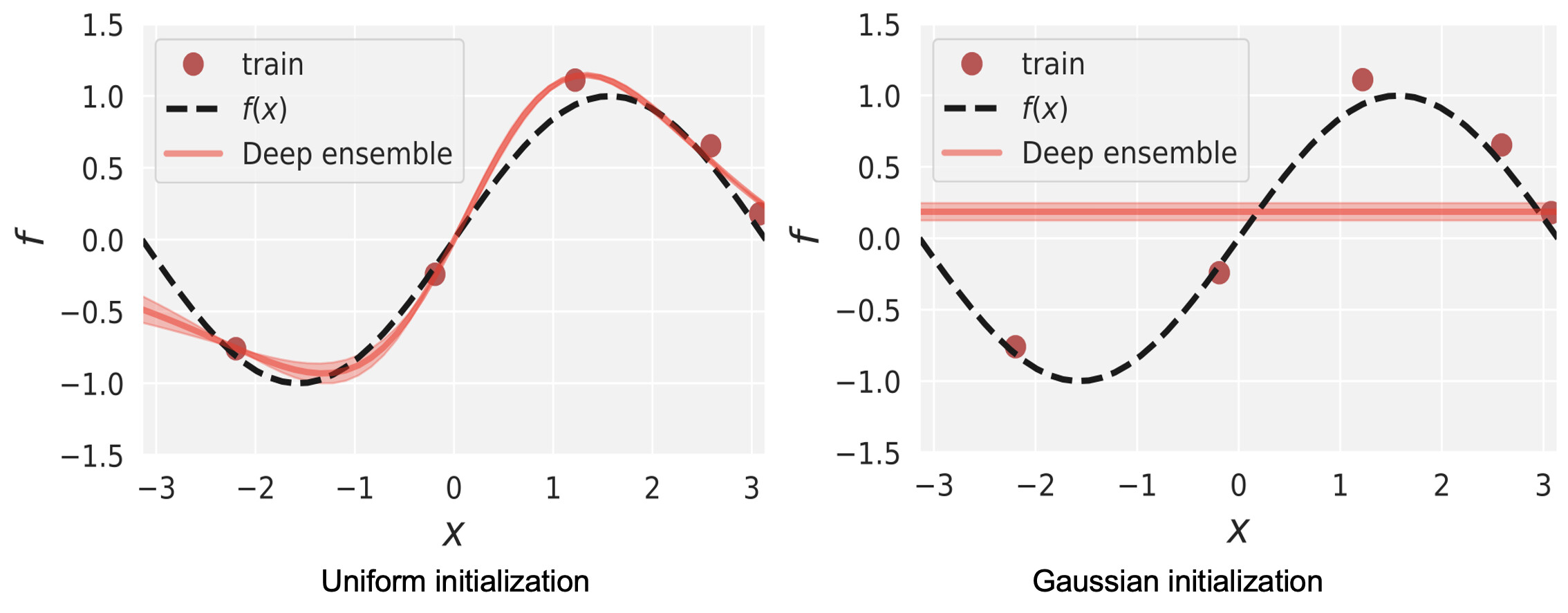
The problem is quite simple. I’m trying to fit an ensemble of 2-layer MLPs with all fully connected layers to the function y = sin(x) with 5 training data points (marked as red dots in the figures below). When I use the default initialization strategy (which, I believe, is a type of uniform initialization) for weights and biases, the model can almost perfectly fit to the training data points. However, when I change the initialization strategy to Gaussian initialization, the model can only learn a constant mean. Does the weight initialization matter that much in this case? I personally don’t think uniform or Gaussian initialization has such a large difference.