Hi~
I use torch.jit.trace to create the model for LibTorch C++.
Python code show as follows:
class ResBlock_W512H15(nn.Module):
def __init__(self, idx=0, filter_num=16, kernelSize=(3, 9), dropValue=0.2, poolSize=4):
super(ResBlock_W512H15, self).__init__()
self.in_ch = (2 ** idx) * filter_num
self.out_ch = (2 ** (idx + 1)) * filter_num
self.poolSize = poolSize
self.bn = nn.BatchNorm2d(self.in_ch)
self.conv = nn.Conv2d(in_channels=self.in_ch,
out_channels=self.out_ch,
kernel_size=kernelSize,
padding=(kernelSize[0]//2, 4))
self.drop = nn.Dropout2d(dropValue)
self.mp = nn.MaxPool2d(kernel_size=(1, poolSize),
stride=None)
def forward(self, x):
shortcut = self.mp(x)
P_top = (self.out_ch - self.in_ch) // 2
P_buttum = (self.out_ch - self.in_ch) - P_top
shortcut = F.pad(shortcut, (0, 0, 0, 0, P_top, P_buttum))
out = x
out = F.relu(self.bn(out))
out = self.drop(out)
out = self.conv(out)
out = self.mp(out)
out += shortcut
return out
class Model_W512H15(nn.Module):
def __init__(self, inChannel=1, filter_num=16, kernelSize=(3, 9), num_out=15, num_categories=4):
super(Model_W512H15, self).__init__()
self.filter_num = filter_num
self.kernelSize = kernelSize
self.num_out = num_out
self.num_categories = num_categories
self.conv1 = nn.Conv2d(in_channels=inChannel,
out_channels=self.filter_num,
kernel_size=self.kernelSize,
padding=(kernelSize[0]//2, 4))
# --- Resblocks
self.ConvBlock0 = ResBlock_W512H15(0, filter_num=self.filter_num, kernelSize=self.kernelSize, poolSize=4)
self.ConvBlock1 = ResBlock_W512H15(1, filter_num=self.filter_num, kernelSize=self.kernelSize, poolSize=4)
self.ConvBlock2 = ResBlock_W512H15(2, filter_num=self.filter_num, kernelSize=self.kernelSize, poolSize=4)
self.ConvBlock3 = ResBlock_W512H15(3, filter_num=self.filter_num, kernelSize=self.kernelSize, poolSize=2)
self.ConvBlock4 = ResBlock_W512H15(4, filter_num=self.filter_num, kernelSize=self.kernelSize, poolSize=2)
self.ConvBlock5 = ResBlock_W512H15(5, filter_num=self.filter_num, kernelSize=self.kernelSize, poolSize=2)
# --- Final
self.final_ch = (2 ** 6) * self.filter_num
self.bn = nn.BatchNorm2d(self.final_ch)
self.m = nn.Softmax(dim=2)
self.fc = nn.ModuleList()
for i in range(self.num_out):
self.fc.append(nn.Linear(self.final_ch, self.num_categories))
def forward(self, x):
out = x # (1,15,512)
out = self.conv1(out) # (16,15,512)
out = self.ConvBlock0(out) # (32,15,128)
out = self.ConvBlock1(out) # (64,15,32)
out = self.ConvBlock2(out) # (128,15,8)
out = self.ConvBlock3(out) # (256,15,4)
out = self.ConvBlock4(out) # (512,15,2)
out = self.ConvBlock5(out) # (1024,15,1)
out = F.relu(self.bn(out))
out = out.permute(0, 3, 2, 1)
out_final = torch.zeros([out.size()[0], self.num_out, self.num_categories]).cuda()
for i in range(self.num_out):
x1 = self.fc[i](out[:, :, i, :])
out_final[:, i, :] = x1[:, 0, :]
out_final = self.m(out_final)
return out_final
device = torch.device('cuda')
model = Model_W512H15(kernelSize=(7, 9)).to(device)
model.eval()
input = torch.ones(1, 1, 15, 512).cuda()
trace_net = torch.jit.trace(model, input)
trace_net.eval()
trace_net.save("CppModel.pt")
And I run the following C++ code:
//--- Load model
string ModulePath = "CppModel.pt";
torch::jit::script::Module module;
module = torch::jit::load(ModulePath);
module.to(at::kCUDA);
module.eval();
//--- Test input
at::Tensor example = torch::ones({ 10, 1, 15, 512 });
vector<torch::jit::IValue> example_i;
example_i.push_back(example.to(at::kCUDA));
try {
auto output = module.forward(example_i).toTensor();
}
catch (std::runtime_error & e) {
std::cerr << e.what() << std::endl;
}
I got the error message as follows:
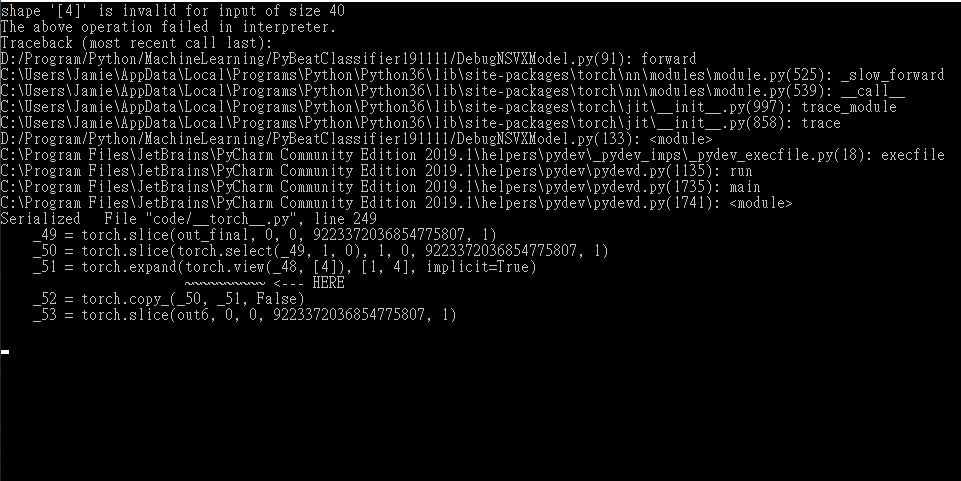
Could someone help me?
Environment
- PyTorch Version (e.g., 1.0): Pytorch 1.3
- Libtorch Version: Nightly version
- OS (e.g., Linux): Window 10
- Visual studio 2019
- How you installed PyTorch (
conda,pip, source): pip - Build command you used (if compiling from source):
- Python version: Python 3.6
- CUDA/cuDNN version: CUDA 9.2
- GPU models and configuration:
- Any other relevant information: