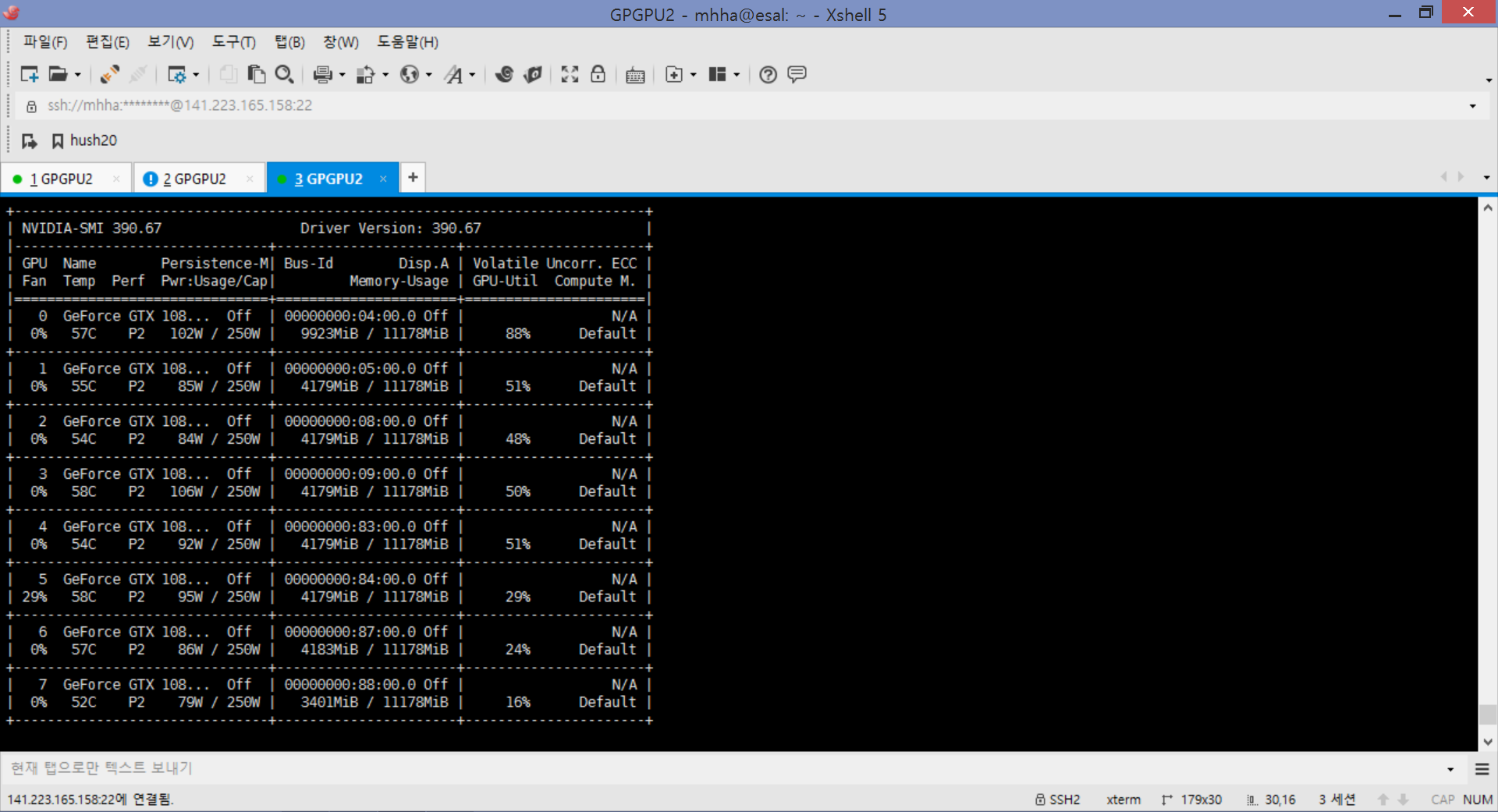
I’m working on classification of ImageNet2012 using VGG16.
I’m currently working with 8 GPUs, which are gtx1080ti.
The problem is that the job allocation is only directed at the 0th GPU. So, they cannot inference with a large batch size.
Below is my code. (The VGG16 parameters were extracted from the pre-trained model.)
from __future__ import print_function
import torch
import torch.nn as nn
import torchvision.datasets as datasets
import torch.backends.cudnn as cudnn
import torchvision.transforms as transforms
from torch.autograd import Variable
import torchvision.models as models
from utils import progress_bar
import os
import VGG16_conv1
import VGG16_conv2
import VGG16_conv3
import VGG16_conv4
import VGG16_conv5
import VGG16_conv6
import VGG16_conv7
import VGG16_conv8
import VGG16_conv9
import VGG16_conv10
import VGG16_conv11
import VGG16_conv12
import VGG16_conv13
import VGG16_linear1
import VGG16_linear2
import VGG16_linear3
use_cuda = torch.cuda.is_available()
best_acc = 0 # best test accuracy
valdir = os.path.join("/home/mhha/", 'val')
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
val_loader = torch.utils.data.DataLoader(
datasets.ImageFolder(valdir, transforms.Compose([
transforms.Scale(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize,
])),
batch_size=100, shuffle=False,
num_workers=4, pin_memory=True)
net = models.vgg16(pretrained=True)
net_conv1 = VGG16_conv1.VGG16_CONV1()
net_conv2 = VGG16_conv2.VGG16_CONV2()
net_conv3 = VGG16_conv3.VGG16_CONV3()
net_conv4 = VGG16_conv4.VGG16_CONV4()
net_conv5 = VGG16_conv5.VGG16_CONV5()
net_conv6 = VGG16_conv6.VGG16_CONV6()
net_conv7 = VGG16_conv7.VGG16_CONV7()
net_conv8 = VGG16_conv8.VGG16_CONV8()
net_conv9 = VGG16_conv9.VGG16_CONV9()
net_conv10 = VGG16_conv10.VGG16_CONV10()
net_conv11 = VGG16_conv11.VGG16_CONV11()
net_conv12 = VGG16_conv12.VGG16_CONV12()
net_conv13 = VGG16_conv13.VGG16_CONV13()
net_linear1 = VGG16_linear1.VGG16_LINEAR1()
net_linear2 = VGG16_linear2.VGG16_LINEAR2()
net_linear3 = VGG16_linear3.VGG16_LINEAR3()
print("saving CONV1 weights")
net_conv1.conv1[0].weight = net.features[0].weight
net_conv1.conv1[0].bias = net.features[0].bias
print("saving CONV2 weights")
net_conv2.conv2[0].weight = net.features[2].weight
net_conv2.conv2[0].bias = net.features[2].bias
print("saving CONV3 weights")
net_conv3.conv3[0].weight = net.features[5].weight
net_conv3.conv3[0].bias = net.features[5].bias
print("saving CONV4 weights")
net_conv4.conv4[0].weight = net.features[7].weight
net_conv4.conv4[0].bias = net.features[7].bias
print("saving CONV5 weights")
net_conv5.conv5[0].weight = net.features[10].weight
net_conv5.conv5[0].bias = net.features[10].bias
print("saving CONV6 weights")
net_conv6.conv6[0].weight = net.features[12].weight
net_conv6.conv6[0].bias = net.features[12].bias
print("saving CONV7 weights")
net_conv7.conv7[0].weight = net.features[14].weight
net_conv7.conv7[0].bias = net.features[14].bias
print("saving CONV8 weights")
net_conv8.conv8[0].weight = net.features[17].weight
net_conv8.conv8[0].bias = net.features[17].bias
print("saving CONV9 weights")
net_conv9.conv9[0].weight = net.features[19].weight
net_conv9.conv9[0].bias = net.features[19].bias
print("saving CONV10 weights")
net_conv10.conv10[0].weight = net.features[21].weight
net_conv10.conv10[0].bias = net.features[21].bias
print("saving CONV11 weights")
net_conv11.conv11[0].weight = net.features[24].weight
net_conv11.conv11[0].bias = net.features[24].bias
print("saving CONV12 weights")
net_conv12.conv12[0].weight = net.features[26].weight
net_conv12.conv12[0].bias = net.features[26].bias
print("saving CONV13 weights")
net_conv13.conv13[0].weight = net.features[28].weight
net_conv13.conv13[0].bias = net.features[28].bias
print("saving FC1 weights")
net_linear1.linear1[0].weight = net.classifier[0].weight
net_linear1.linear1[0].bias = net.classifier[0].bias
print("saving FC2 weights")
net_linear2.linear2[0].weight = net.classifier[3].weight
net_linear2.linear2[0].bias = net.classifier[3].bias
print("saving FC3 weights")
net_linear3.linear3[0].weight = net.classifier[6].weight
net_linear3.linear3[0].bias = net.classifier[6].bias
if use_cuda:
net_conv1.cuda()
net_conv1 = torch.nn.DataParallel(net_conv1, device_ids=range(torch.cuda.device_count()))
net_conv2.cuda()
net_conv2 = torch.nn.DataParallel(net_conv2, device_ids=range(torch.cuda.device_count()))
net_conv3.cuda()
net_conv3 = torch.nn.DataParallel(net_conv3, device_ids=range(torch.cuda.device_count()))
net_conv4.cuda()
net_conv4 = torch.nn.DataParallel(net_conv4, device_ids=range(torch.cuda.device_count()))
net_conv5.cuda()
net_conv5 = torch.nn.DataParallel(net_conv5, device_ids=range(torch.cuda.device_count()))
net_conv6.cuda()
net_conv6 = torch.nn.DataParallel(net_conv6, device_ids=range(torch.cuda.device_count()))
net_conv7.cuda()
net_conv7 = torch.nn.DataParallel(net_conv7, device_ids=range(torch.cuda.device_count()))
net_conv8.cuda()
net_conv8 = torch.nn.DataParallel(net_conv8, device_ids=range(torch.cuda.device_count()))
net_conv9.cuda()
net_conv9 = torch.nn.DataParallel(net_conv9, device_ids=range(torch.cuda.device_count()))
net_conv10.cuda()
net_conv10 = torch.nn.DataParallel(net_conv10, device_ids=range(torch.cuda.device_count()))
net_conv11.cuda()
net_conv11 = torch.nn.DataParallel(net_conv11, device_ids=range(torch.cuda.device_count()))
net_conv12.cuda()
net_conv12 = torch.nn.DataParallel(net_conv12, device_ids=range(torch.cuda.device_count()))
net_conv13.cuda()
net_conv13 = torch.nn.DataParallel(net_conv13, device_ids=range(torch.cuda.device_count()))
net_linear1.cuda()
net_linear1 = torch.nn.DataParallel(net_linear1, device_ids=range(torch.cuda.device_count()))
net_linear2.cuda()
net_linear2 = torch.nn.DataParallel(net_linear2, device_ids=range(torch.cuda.device_count()))
net_linear3.cuda()
net_linear3 = torch.nn.DataParallel(net_linear3, device_ids=range(torch.cuda.device_count()))
cudnn.benchmark = True
criterion = nn.CrossEntropyLoss()
def test():
global best_acc
net_conv1.eval()
net_conv2.eval()
net_conv3.eval()
net_conv4.eval()
net_conv5.eval()
net_conv6.eval()
net_conv7.eval()
net_conv8.eval()
net_conv9.eval()
net_conv10.eval()
net_conv11.eval()
net_conv12.eval()
net_conv13.eval()
net_linear1.eval()
net_linear2.eval()
net_linear3.eval()
test_loss = 0
correct = 0
total = 0
for batch_idx, (inputs, targets) in enumerate(val_loader):
if use_cuda:
inputs, targets = inputs.cuda(), targets.cuda()
inputs, targets = Variable(inputs), Variable(targets)
outputs_conv1 = net_conv1(inputs)
outputs_conv2 = net_conv2(outputs_conv1)
outputs_conv3 = net_conv3(outputs_conv2)
outputs_conv4 = net_conv4(outputs_conv3)
outputs_conv5 = net_conv5(outputs_conv4)
outputs_conv6 = net_conv6(outputs_conv5)
outputs_conv7 = net_conv7(outputs_conv6)
outputs_conv8 = net_conv8(outputs_conv7)
outputs_conv9 = net_conv9(outputs_conv8)
outputs_conv10 = net_conv10(outputs_conv9)
outputs_conv11 = net_conv11(outputs_conv10)
outputs_conv12 = net_conv12(outputs_conv11)
outputs_conv13 = net_conv13(outputs_conv12)
outputs_linear1 = net_linear1(outputs_conv13)
outputs_linear2 = net_linear2(outputs_linear1)
outputs_linear3 = net_linear3(outputs_linear2)
loss = criterion(outputs_linear3, targets)
test_loss += loss.data
_, predicted = torch.max(outputs_linear3.data, 1)
total += targets.size(0)
correct += predicted.eq(targets.data).cpu().sum()
progress_bar(batch_idx, len(val_loader), 'Loss: %.3f | Acc: %.3f%% (%d/%d)'
% (test_loss/(batch_idx+1), 100.*float(correct)/float(total), correct, total))
# Save checkpoint.
acc = 100.*correct/total
if acc > best_acc:
print('Saving..')
state = {
'net_conv1': net_conv1.module if use_cuda else net_conv1,
'net_conv2': net_conv2.module if use_cuda else net_conv2,
'net_conv3': net_conv3.module if use_cuda else net_conv3,
'net_conv4': net_conv4.module if use_cuda else net_conv4,
'net_conv5': net_conv5.module if use_cuda else net_conv5,
'net_conv6': net_conv6.module if use_cuda else net_conv6,
'net_conv7': net_conv7.module if use_cuda else net_conv7,
'net_conv8': net_conv8.module if use_cuda else net_conv8,
'net_conv9': net_conv9.module if use_cuda else net_conv9,
'net_conv10': net_conv10.module if use_cuda else net_conv10,
'net_conv11': net_conv11.module if use_cuda else net_conv11,
'net_conv12': net_conv12.module if use_cuda else net_conv12,
'net_conv13': net_conv13.module if use_cuda else net_conv13,
'net_linear1': net_linear1.module if use_cuda else net_linear1,
'net_linear2': net_linear2.module if use_cuda else net_linear2,
'net_linear3': net_linear3.module if use_cuda else net_linear3,
'acc': acc,
}
if not os.path.isdir('checkpoint'):
os.mkdir('checkpoint')
torch.save(state, './checkpoint/ckpt_vgg16_layer_by_layer_v1.t7')
best_acc = acc
# Train+inference vs. Inference
print("Layer by layer VGG16 Test \n")
test()
Where is the problem??