I was playing with simple neural style transfer model, using the pretrained vgg model in torchvision, and followed the official advice, I preprocessed the input images (content, style, however input is a random noise image, so I didn’t preprocess it) before training (see prep function below), and then post processed the images (content, style, optimized input) when training is done (see inv_prep below).
The problem is, seems like preprocessing gave me worse results, and I removed preprocessing and tried again, which gave me better results, both with the same initial input noise image.
# below, no mean/std preprocessing, only image Scale + axis-moving
prep = thv.transforms.Compose([
thv.transforms.Scale(200),
thv.transforms.Lambda(lambda x: np.moveaxis(np.array(x), 2, 0)),
thv.transforms.Lambda(lambda x: th.from_numpy(x.astype('float32'))),
thv.transforms.Lambda(lambda x: x.unsqueeze(0))
])
inv_prep = thv.transforms.Compose([
thv.transforms.Lambda(lambda x: x.squeeze(0)),
thv.transforms.Lambda(lambda x: (x.numpy().clip(0,255).astype('uint8'))),
thv.transforms.Lambda(lambda x: np.moveaxis(np.array(x), 0, 2)),
])
# below, with mean/std preprocessing, and yes I know I could use ToPILImage to convert tensors back to images
prep = thv.transforms.Compose([
thv.transforms.Scale(200),
thv.transforms.ToTensor(), # need to do this before applying mean/std transformation
thv.transforms.Normalize(mean=mean, std=std),
thv.transforms.Lambda(lambda x: x.unsqueeze(0))
])
inv_prep = thv.transforms.Compose([
thv.transforms.Lambda(lambda x: x.squeeze(0)),
thv.transforms.Normalize(mean=[0,0,0], std=1/std),
thv.transforms.Normalize(mean=-mean, std=[1,1,1]),
thv.transforms.Lambda(lambda x: (x.numpy().clip(0,1) * 255).astype('uint8')),
thv.transforms.Lambda(lambda x: np.moveaxis(np.array(x), 0, 2)),
])
This is the result image I got, with mean/std preprocessing, 100 itertaions:
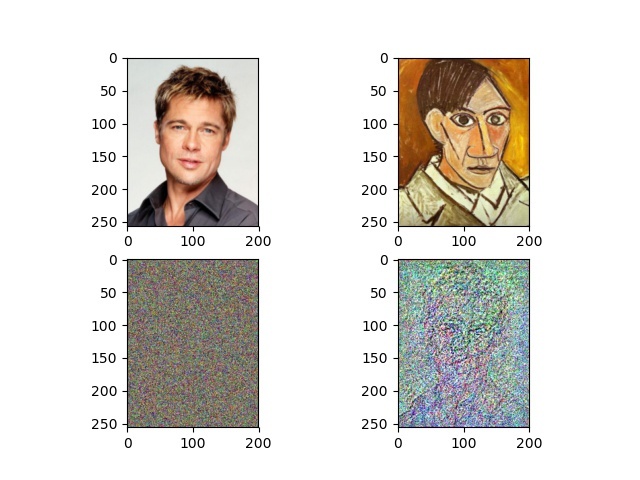
This is the result image I got, without preprocessing, 100 itertaions:
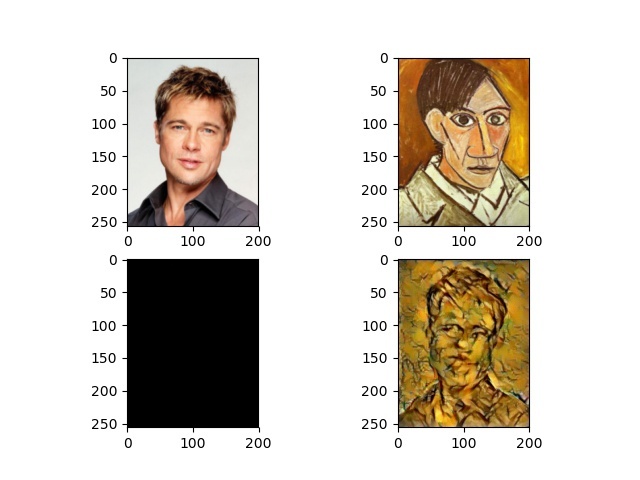
Why is that? Anything I did wrong? I checked the final optimized input, the pixel values range from around [-50, 50], and I’m not sure how to convert them back to real image pixel values, and I think this is the problem I didn’t get right, which gives me bad image result as shown in the first pic (although I still can see the shape of Peter :-|).