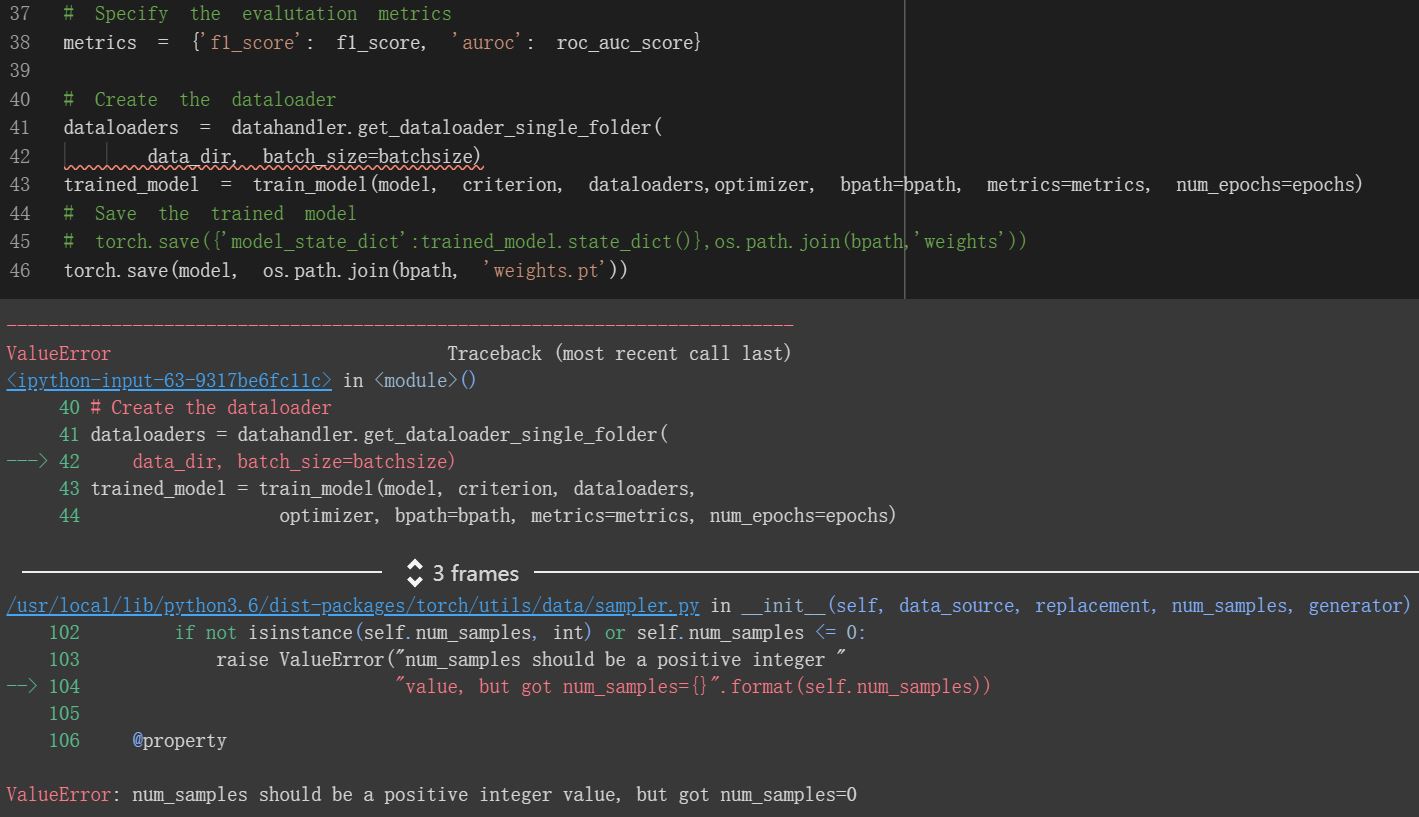
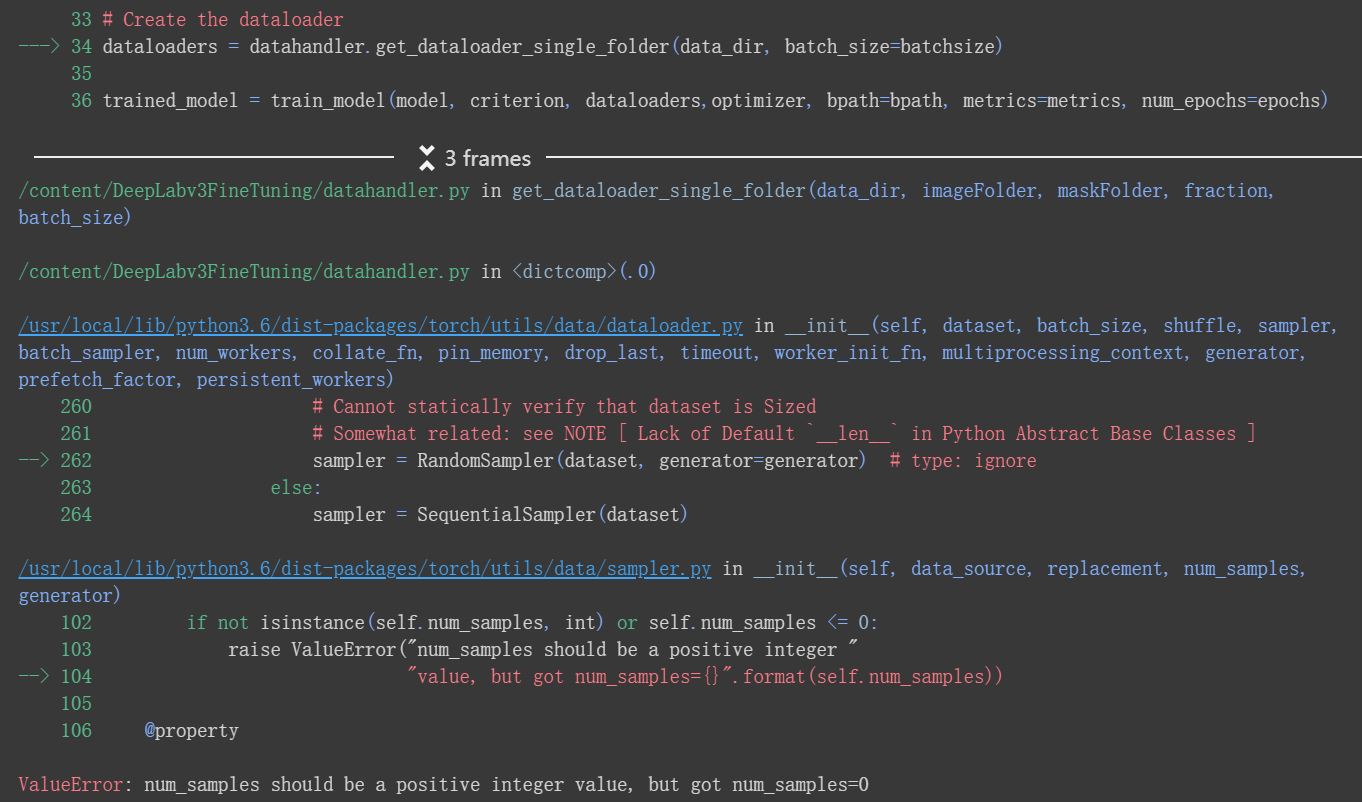
File “/usr/local/lib/python3.6/dist-packages/torch/utils/data/dataloader.py”, line 224, in init
sampler = RandomSampler(dataset, generator=generator)
File “/usr/local/lib/python3.6/dist-packages/torch/utils/data/sampler.py”, line 96, in init
“value, but got num_samples={}”.format(self.num_samples))
ValueError: num_samples should be a positive integer value, but got num_samples=0
Hi. Can you please check that the path to dataset is correct ? I had a similar issue and providing the correct path to dataset solved that.
How can I make the generator give the data I expect, can you give me some guidance?
Hi. So, I don’t think the issue is related to the generator. The generator here is basically a PyTorch generator object that manages the state of the algorithm which produces pseudo random numbers like which device to use (cpu/gpu), state of the generator, setting the seed etc. https://pytorch.org/docs/stable/generated/torch.Generator.html
For your problem, you just need to provide the right path to the dataset.
Can you provide a bit more details here like what is the generator in your case and what kind of dataset are you using?
I am using some pictures labeled as voc dataset (JPEGImages and SegmentationClass), and I want to use it in another model(image and mask).I put it directly into the file.How does the image convert into mask? is there any format?


my dataset and the annotated road crack image database that used in the model
Hi. So the images that you have in 1, 2, 3, 4 are basically the segmentation masks. The difference in their color represents different class/label.
It looks like that the model that you are using right now does handle the case when the mask is rgb instead of grayscale.
Just change the mask color from grayscale to rgb if your image has 3 channels.
I hope this gives some clarity.
1 Like
I change maskcolormode to rgb but the image still not load in,
to apply this model what else should I do, can you give me some guidance?
May the reason be that only 4 images can not be divided into the train and val dataset in the network?
So I try part of Voc in this model, but the size of image is not the same, how should I make them the same?
Hi. Yes the number of images could be a reason depending on how you are loading them. To make the images to the same size, you can use a custom transform something like this:
# Transforms for DataLoader
class Resize(object):
""" Resize Image and/or Masks """
def __init__(self, height, width):
"""
Args:
height (int): resize to height
width (int): resize to width
"""
self.height = height
self.width = width
def __call__(self, sample):
"""
Args:
sample (dict): input image/mask pair
Returns:
dict: image/mask pair as ndarray
"""
image, mask = sample['image'], sample['mask']
dim = (self.width, self.height)
image = image.resize(dim)
mask = mask.resize(dim)
return {'image': image,
'mask': mask}
NOTE that the images in the above Resize transform are loaded using PIL.Image.
Don’t forget to convert the above images to tensor by either using the ToTensor transform as below:
# Convert Image from Numpy to Tensor
class ToTensor(object):
""" Convert ndarray to Tensor """
def __call__(self, sample):
"""
Args:
sample (dict): input image/mask pair
Returns:
torch Tensor: image/mask tensor
"""
image, mask = sample['image'], sample['mask']
image = np.asarray(image)
mask = np.asarray(mask)
if len(image.shape) == 3:
image = image.transpose(2, 0, 1)
if len(mask.shape) == 2:
mask = mask.reshape((1,) + mask.shape)
if len(image.shape) == 2:
image = image.reshape((1,) + image.shape)
return {'image': torch.from_numpy(np.array(image)),
'mask': torch.from_numpy(np.array(mask))}
Then you can setup these transforms:
transforms.Compose([Resize(330, 422), ToTensor()])
The reason for writing these transforms instead of using the built in ones is due to image as feature and another image as label and we need to apply transforms to both so as to get a image/mask pair.
Hope this helps 
Hi. So, you need to change your dataloader from that GitHub repository as below to make it work with the VOC segmentation dataset.
import torch
import torchvision
from torch.utils.data import Dataset
from PIL import Image
import glob
import numpy as np
class SegmentationDataset(Dataset):
"""Segmentation Dataset"""
def __init__(self, root_dir: str, image_dir: str, mask_dir: str,
transform=None, seed: int = None, fraction: float = None,
subset: str = None, imagecolormode: str = 'rgb',
maskcolormode: str = 'rgb'):
"""
Args:
root_dir (str): dataset dir path
image_dir (str): input image dir name
mask_dir (str): mask image dir name
transform: PyTorch data transform
seed (int): random seed for reproducibility
fraction (float): dataset train/test split percentage
subset (str): subset from existing dataset
imagecolormode (str): input image color mode
maskcolormode (str): input mask color mode
"""
self.color_dict = {'rgb': 1, 'grayscale': 0}
assert (imagecolormode in ['rgb', 'grayscale'])
assert (maskcolormode in ['rgb', 'grayscale'])
self.imagecolorflag = self.color_dict[imagecolormode]
self.maskcolorflag = self.color_dict[maskcolormode]
self.root_dir = root_dir
self.transform = transform
if not fraction:
# UPDATE: Get the Segmentation Masks Before Images
self.mask_names = sorted(
glob.glob(os.path.join(self.root_dir, mask_dir, '*')))
# UPDATE: Get images with the names in the mask_names list but with updated path and '.jpg' extension
self.image_names = sorted(
os.path.join(self.root_dir, image_dir, fname.split('/')[4].split('.png')[0] + '.jpg')
for fname in self.mask_names)
else:
assert (subset in ['Train', 'Test'])
self.fraction = fraction
# UPDATE: Get the Segmentation Masks Before Images
self.mask_list = np.array(
sorted(glob.glob(os.path.join(self.root_dir, mask_dir, '*'))))
# UPDATE: Get images with the names in the mask_names list but with updated path and '.jpg' extension
self.image_list = np.array(
sorted(os.path.join(self.root_dir, image_dir, fname.split('/')[4].split('.png')[0] + '.jpg')
for fname in self.mask_list))
if seed:
np.random.seed(seed)
indices = np.arange(len(self.image_list))
np.random.shuffle(indices)
self.image_list = self.image_list[indices]
self.mask_list = self.mask_list[indices]
if subset == 'Train':
self.image_names = self.image_list[:int(
np.ceil(len(self.image_list) * (1 - self.fraction)))]
self.mask_names = self.mask_list[:int(
np.ceil(len(self.mask_list) * (1 - self.fraction)))]
else:
self.image_names = self.image_list[int(
np.ceil(len(self.image_list) * (1 - self.fraction))):]
self.mask_names = self.mask_list[int(
np.ceil(len(self.mask_list) * (1 - self.fraction))):]
def __getitem__(self, idx):
"""
Args:
idx (int): index of input image
Returns:
dict: image and mask image
"""
img_name = self.image_names[idx]
mask_name = self.mask_names[idx]
image = Image.open(img_name)
mask = Image.open(mask_name)
sample = {'image': image, 'mask': mask}
if self.transform:
sample = self.transform(sample)
return sample
def __len__(self):
"""
Returns: length of dataset
"""
return len(self.image_names)
Now you can call the above dataset class as follows:
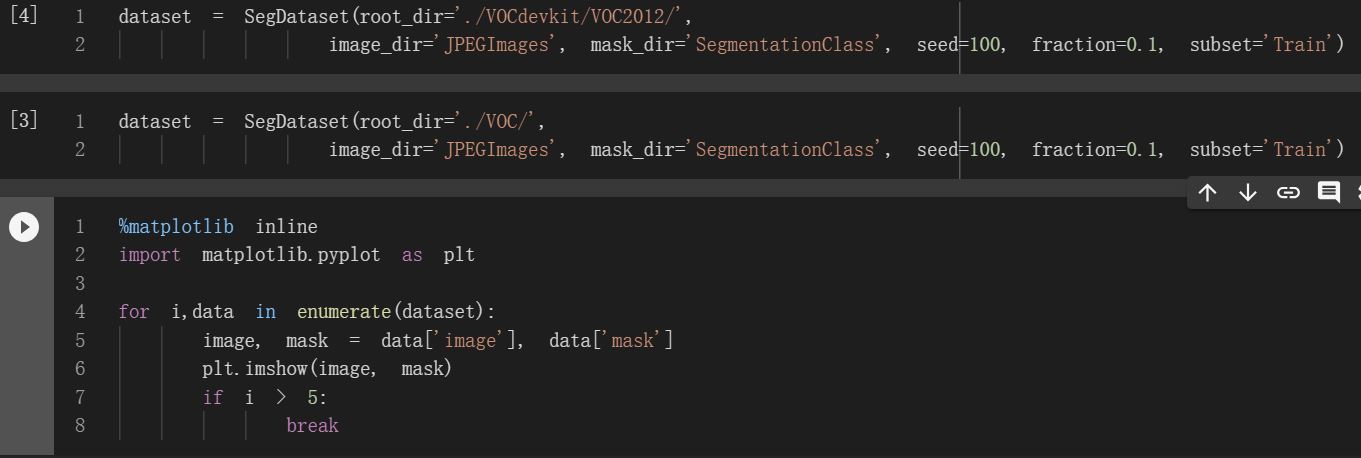
dataset = SegmentationDataset(root_dir='./VOCdevkit/VOC2012/', image_dir='JPEGImages', mask_dir='SegmentationClass', seed=100, fraction=0.1, subset='Train')
and everything should work. You can test the image/mask pairs using the following code:
import matplotlib.pyplot as plt
for i,data in enumerate(dataset):
image, mask = data['image'], data['mask']
show_image_mask(image, mask)
if i > 5:
break
Hope this helps
So grateful for you help and awesome code!
But the train not begin by running the command
May it be that the train and test dataset not splited successfully?
plt.imshow might work, but currently you are passing an invalid image path, thus the image cannot be loaded.
Ok. So I instantiated the dataset line just to explain the concept and test it out, but you don’t need that. Just make changes to the SegmentationDataset class and that’s it. Nothing else needs to be changed in your code from that GitHub repository. It has the code to instantiate the dataset and split into train and test sets in the get_dataloader_single_folder function.
Also up there, plt.imshow() takes only one image at a time. So if you just do plt.imshow(image), that should work.
So grateful. But when I only change imageFolder to image_dir in SegDataset it gives me TypeError of init(), but if I change it to imageFolder , SegDataset can not works well alone, what cause the problem and how should I define them?
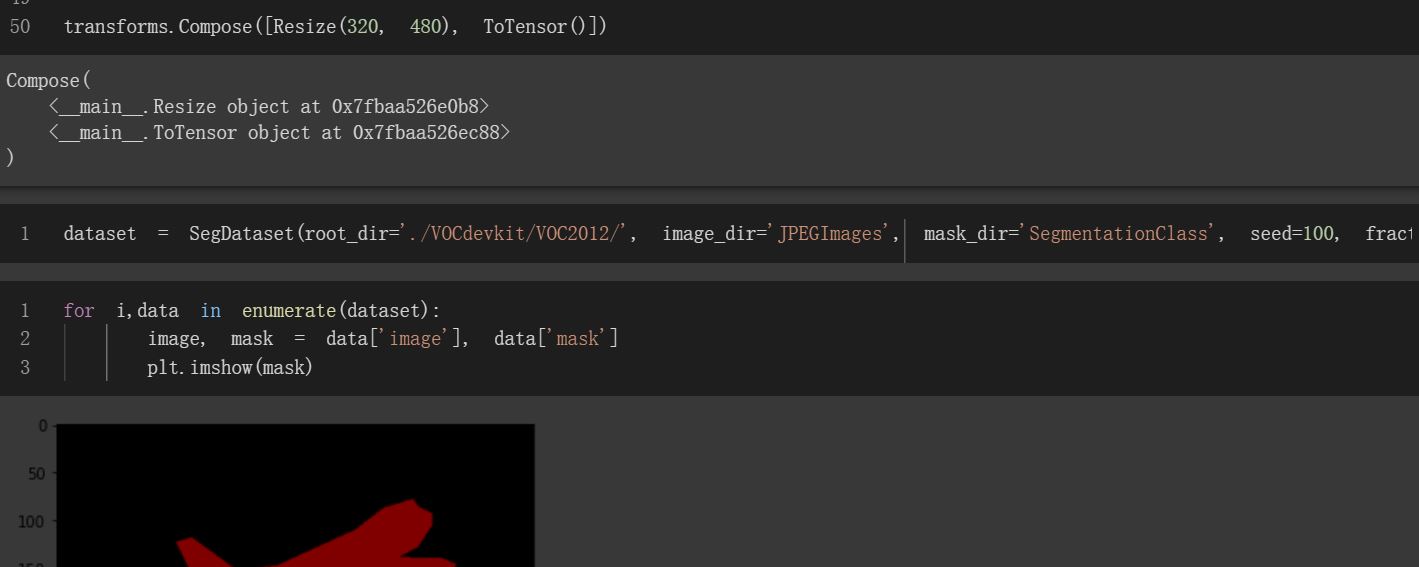
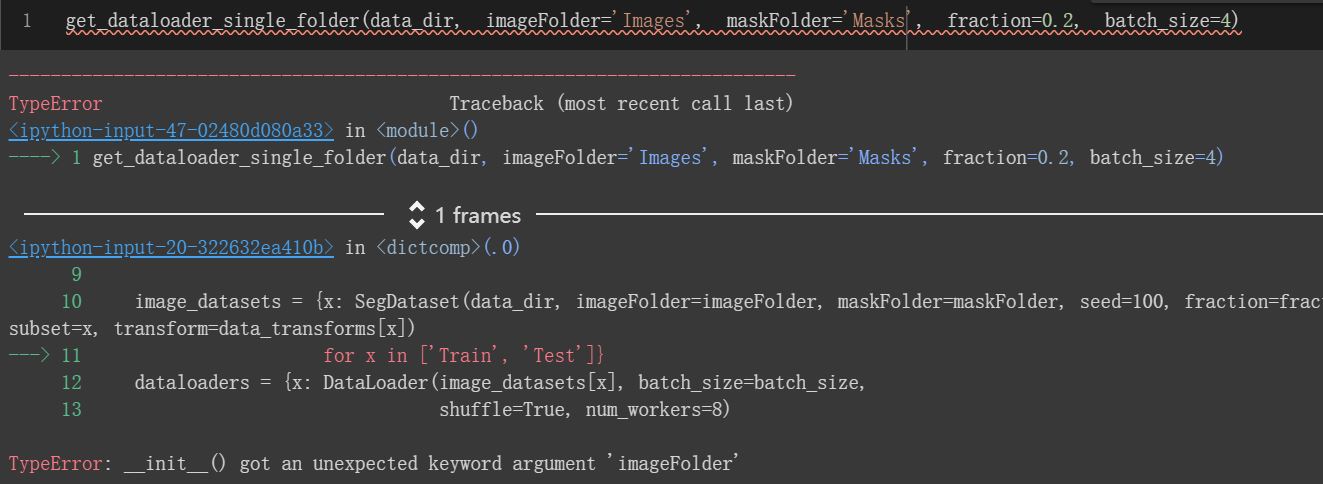
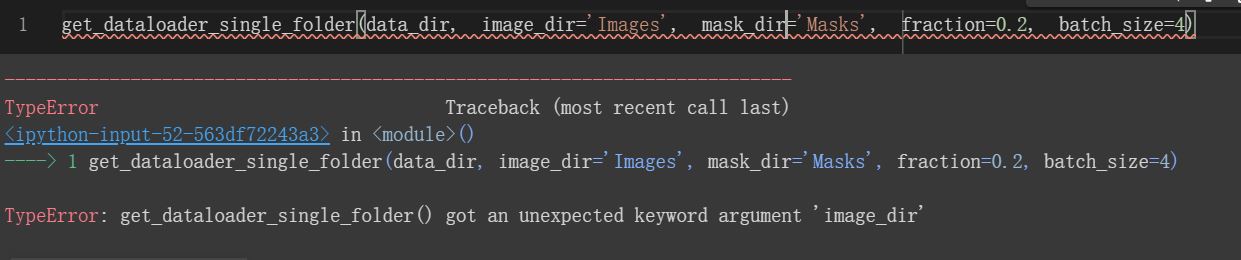
Thanks you very much to teach me the original function, I conduct a breakpoints debugging in colab and the image has been read, but something still wrong with the dataloader, can you give me some suggestions?