I would like to modify the DCGAN example to support images sizes greater than 64x64. The next upper level is to generate 128x128 images and I have seen many discussions (old and new) about that. For example, here and here.
The trick is to modify Generator and Discriminator but it seems that only that modification is not enough. Here is the suggested modification:
# Generator Code
class Generator(nn.Module):
def __init__(self, ngpu):
super(Generator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
# input is Z, going into a convolution
nn.ConvTranspose2d( nz, ngf * 16, 4, 1, 0, bias=False),
nn.BatchNorm2d(ngf * 16),
nn.ReLU(True),
# state size. ``(ngf*16) x 4 x 4``
nn.ConvTranspose2d(ngf * 16, ngf * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 8),
nn.ReLU(True),
# state size. ``(ngf*8) x 8 x 8``
nn.ConvTranspose2d( ngf * 8, ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
# state size. ``(ngf*4) x 16 x 16``
nn.ConvTranspose2d( ngf * 4, ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 2),
nn.ReLU(True),
# state size. ``(ngf*2) x 32 x 32``
nn.ConvTranspose2d( ngf * 2, ngf, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(True),
# state size. (ngf) x 64 x 64
nn.ConvTranspose2d( ngf, nc, 4, 2, 1, bias=False),
nn.Tanh()
# state size. ``(nc) x 128 x 128``
)
# Discriminator Code
class Discriminator(nn.Module):
def __init__(self, ngpu):
super(Discriminator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
# input is ``(nc) x 128 x 128``
nn.Conv2d(nc, ndf, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# state size. ``(ndf) x 64 x 64``
nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
# state size. ``(ndf*2) x 32 x 32``
nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
# state size. ``(ndf*4) x 16 x 16``
nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 8),
nn.LeakyReLU(0.2, inplace=True),
# state size. ``(ndf*8) x 8 x 8``
nn.Conv2d(ndf * 8, ndf * 16, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 16),
nn.LeakyReLU(0.2, inplace=True),
# state size. ``(ndf*16) x 4 x 4``
nn.Conv2d(ndf * 16, 1, 4, 1, 0, bias=False),
nn.Sigmoid()
)
That looks fine and you can see the output below:
Generator(
(main): Sequential(
(0): ConvTranspose2d(100, 1024, kernel_size=(4, 4), stride=(1, 1), bias=False)
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): ConvTranspose2d(1024, 512, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(4): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): ConvTranspose2d(512, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(7): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(8): ReLU(inplace=True)
(9): ConvTranspose2d(256, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(10): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(11): ReLU(inplace=True)
(12): ConvTranspose2d(128, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(13): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(14): ReLU(inplace=True)
(15): ConvTranspose2d(64, 3, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(16): Tanh()
)
)
Discriminator(
(main): Sequential(
(0): Conv2d(3, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): LeakyReLU(negative_slope=0.2, inplace=True)
(2): Conv2d(64, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(4): LeakyReLU(negative_slope=0.2, inplace=True)
(5): Conv2d(128, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(6): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(7): LeakyReLU(negative_slope=0.2, inplace=True)
(8): Conv2d(256, 512, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(9): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(10): LeakyReLU(negative_slope=0.2, inplace=True)
(11): Conv2d(512, 1024, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(12): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(13): LeakyReLU(negative_slope=0.2, inplace=True)
(14): Conv2d(1024, 1, kernel_size=(4, 4), stride=(1, 1), bias=False)
(15): Sigmoid()
)
However, using the same dataset, I see that the loss functions become flat very quickly and the final image is completely noisy.
Starting Training Loop...
[0/5][0/1583] Loss_D: 2.3036 Loss_G: 21.0460 D(x): 0.7720 D(G(z)): 0.7563 / 0.0000
[0/5][50/1583] Loss_D: 0.0161 Loss_G: 50.8019 D(x): 0.9928 D(G(z)): 0.0000 / 0.0000
[0/5][100/1583] Loss_D: 0.0000 Loss_G: 50.0115 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[0/5][150/1583] Loss_D: 0.0000 Loss_G: 49.3807 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[0/5][200/1583] Loss_D: 0.0000 Loss_G: 48.9803 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[0/5][250/1583] Loss_D: 0.0000 Loss_G: 48.4963 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[0/5][300/1583] Loss_D: 0.0000 Loss_G: 48.2999 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[0/5][350/1583] Loss_D: 0.0000 Loss_G: 47.8072 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[0/5][400/1583] Loss_D: 0.0000 Loss_G: 47.7194 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
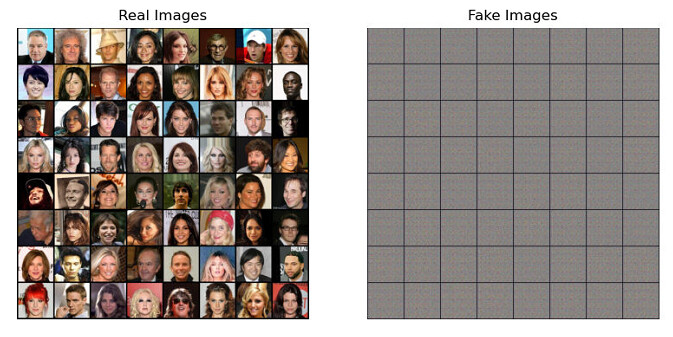
I don’t know if the original images size has to be changed, but Celeba image sizes are 178x218. So it should be fine. Any idea about that?