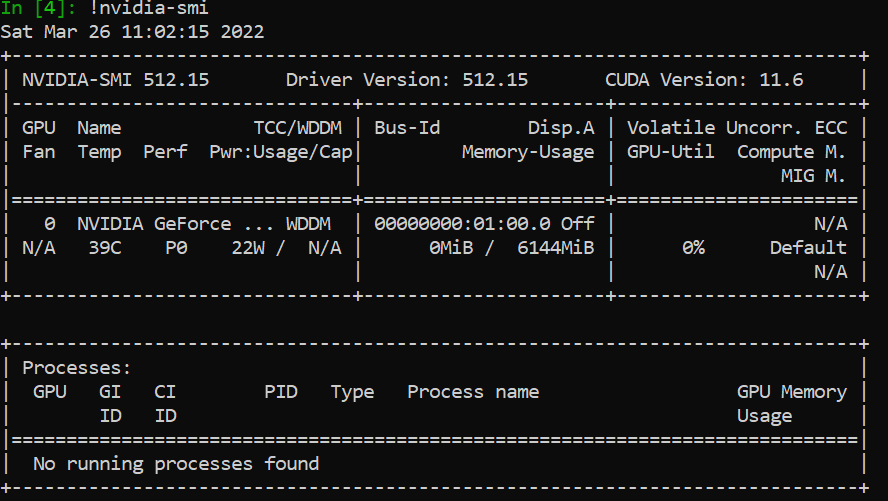
I’m trying to train yolov5s with bdd100k on my GPU locally and getting this error although my GPU check is correctly done. I installed latest version of cuda and pytorch.
ERROR: github: up to date with GitHub - ultralytics/yolov5: YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite
fatal: cannot change to ‘C:\Users\Luka\Desktop\Berkeley’: No such file or directory
Traceback (most recent call last):
File “C:\Users\Luka\Desktop\Berkeley dataset\yolov5s_bdd100k\yolov5\train.py”, line 643, in
main(opt)
File “C:\Users\Luka\Desktop\Berkeley dataset\yolov5s_bdd100k\yolov5\train.py”, line 525, in main
device = select_device(opt.device, batch_size=opt.batch_size)
File “C:\Users\Luka\Desktop\Berkeley dataset\yolov5s_bdd100k\yolov5\utils\torch_utils.py”, line 61, in select_device
assert torch.cuda.is_available() and torch.cuda.device_count() >= len(device.replace(‘,’, ‘’)),
AssertionError: Invalid CUDA ‘–device 0’ requested, use ‘–device cpu’ or pass valid CUDA device(s)
AND after that I do nvidia-smi