Hi there,
When I train yolov5 pytorch on my custom dataset, I tried an experiment.
Ep1: Firstly, I train my dataset (folder Dataset1) with args ‘agment’ = True. Then I save all image augmentation and label files when it create_dataLoader to Dataset2 folder (with train/val split like Dataset1).
Ep2: Next, I trained model with this augmentation dataset (Dataset2) and set up ‘augment’=False.
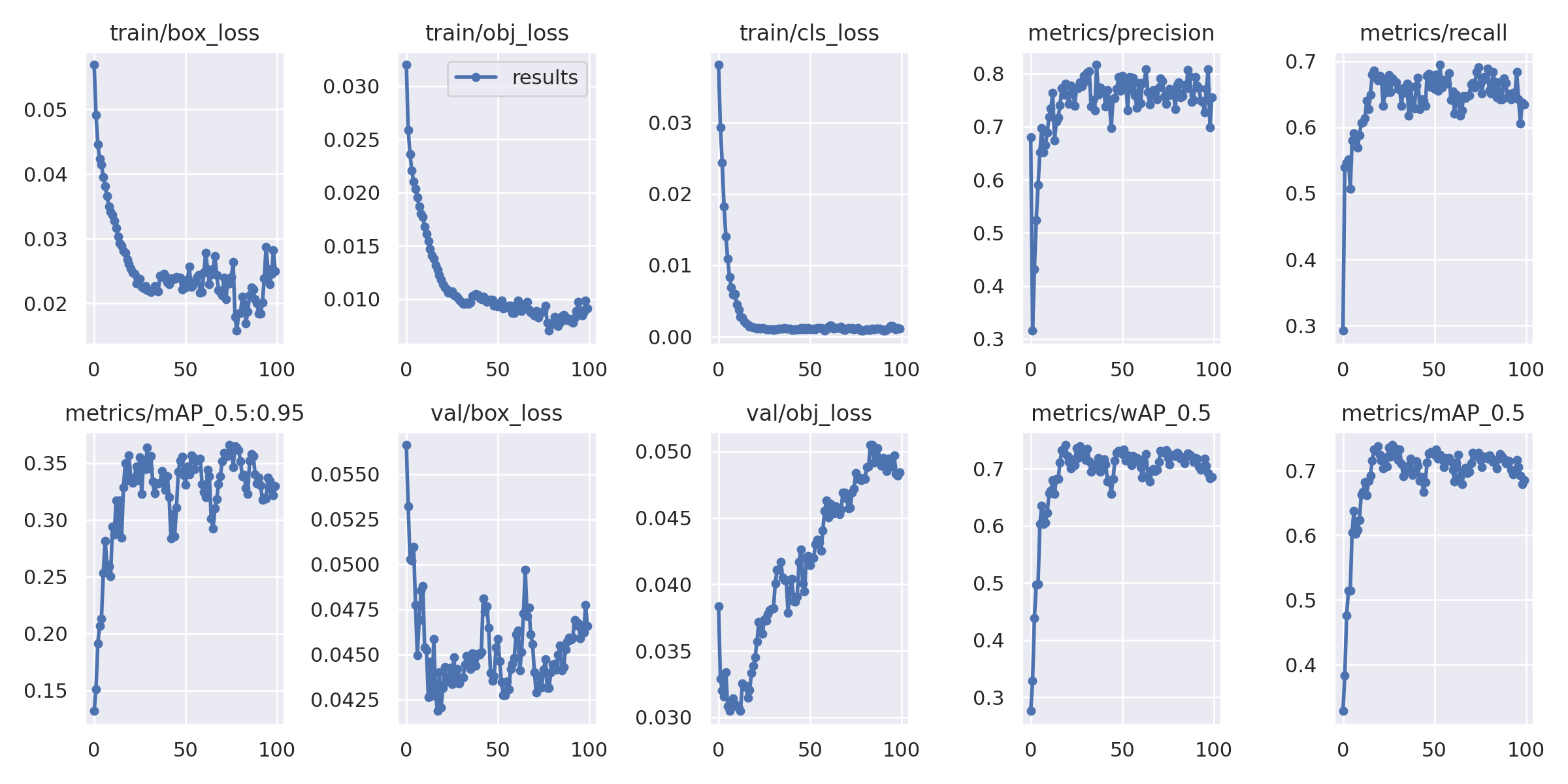
This problem is, the Ep1 (training with ‘augment’ = True) got the better results than Ep2 which new augment data I saved. I get map@.5 = 0.978 on Ep1 and map@.5=0.685 on Ep2 .I don’t know why results are different, whereas I checked results between two approaches many times.
Below is result I training Dataset2.
Thanks a lot <3
Based on this usage of the augment argument, the data and labels are augmented in each iteration and thus epoch. If you are randomly transforming the data only once and load it afterwards, you wouldn’t use any data augmentation anymore and are feeding static input to the model.
Tks so much, I understood. I’m joining a competition belong to data centric. I must prepare a best dataset for yolov5 model to get the best result on map@.5.
The training process limited in 100 epoch, 3000 images and not use augment argument. So I prepare a augmented dataset before training process. Are u have any idea to get the best result equivalent with when we use augment args.
If I understand your use case correctly, you are not allowed to use data augmentation during the training, but would like to achieve a similar performance with a static dataset?
If so, I wouldn’t know of a good technique to act as a replacement for data augmentation. Maybe try to increase the regularization through dropout layers, weight decay etc.
Yeah, that right. And I do not allowed to change the hyper parameter or structure from the original model. Any thing I can make better is prepare the best dataset.