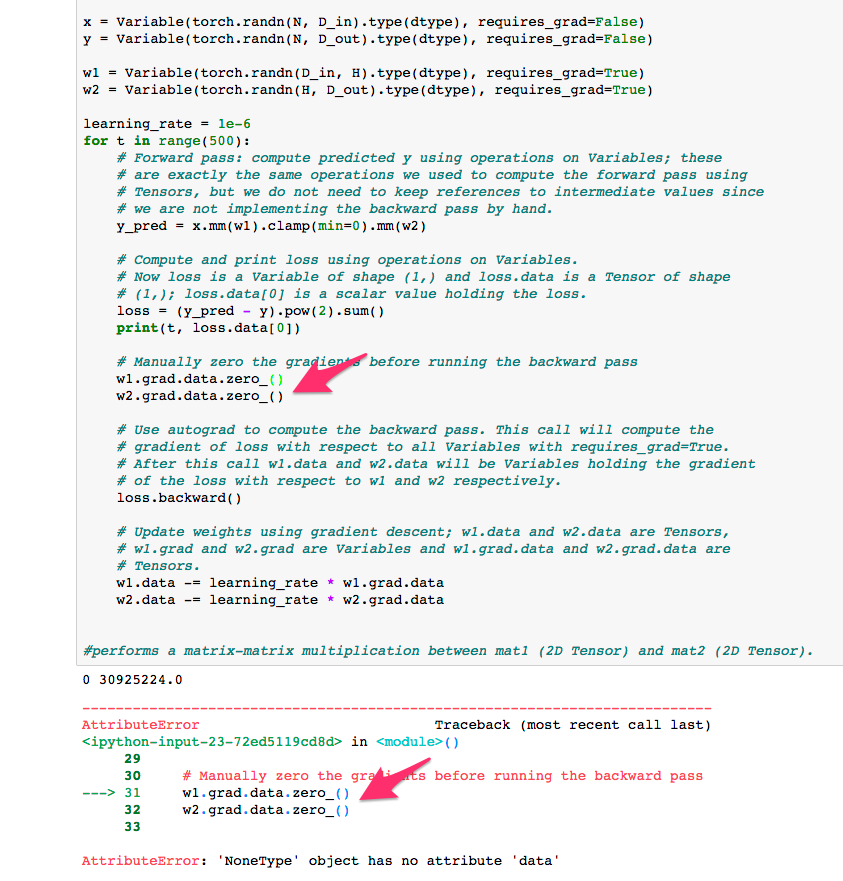
Hi,
I’m trying to use an optimizer only on a part of the module parameters. Should I call module.zero_grad() instead of optimizer.zero_grad() if there are other layers between the loss and layer that i’m training?
And what if I need to train only the last layer(right before the loss) of a module? The gradients for the previous layers wouldn’t be computed at all. So there is no difference between calling module.zero_grad() and calling optimizer.zero_grads(), right?
As @chenyuntc explained, if you pass all parameters of your model to the optimizer, both calls will be equal.
However, there might be use cases where you would like to use different optimizers for different parts of your model. In such a case, model.zero_grad() would clear all parameters of the model, while the optimizerX.zero_grad() call will just clean the gradients of the parameters that were passed to it.
For example ,when we create an optimizer like this:
optimizer_ft=optim.SGD(model_ft.parameters(),lr=0.001,momentum=0.9)
we will add the model’s parameters to this optimizer,so when we call the function optimizer.zero_grad() it will update these parameters ,but if there is another model which did’t register this optimizer, optimizer.zero_grad() will not update it’s grad