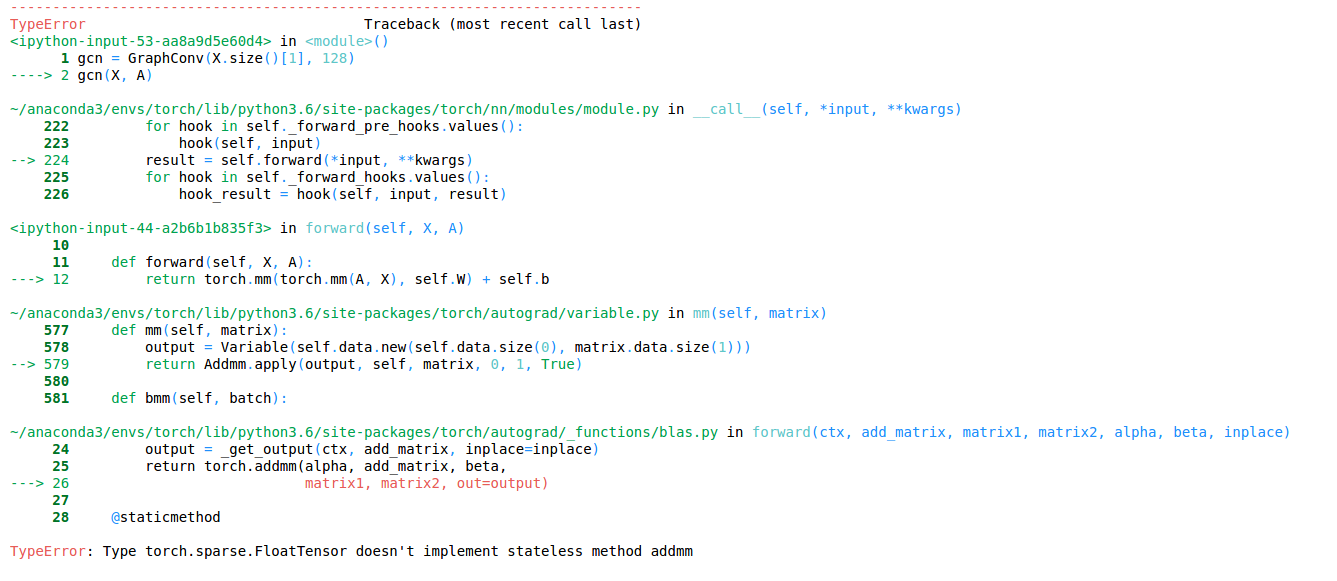
Hi everyone,
I am trying to implement graph convolutional layer (as described in Semi-Supervised Classification with Graph Convolutional Networks) in PyTorch.
For this I need to perform multiplication of the dense feature matrix X by a sparse adjacency matrix A (sparse x dense -> dense). I don’t need to compute the gradients with respect to the sparse matrix A.
As mentioned in this thread, torch.mm should work in this case, however, I get the
TypeError: Type torch.sparse.FloatTensor doesn't implement stateless method addmm
class GraphConv(nn.Module):
def __init__(self, size_in, size_out):
super(GraphConv, self).__init__()
self.W = nn.parameter.Parameter(torch.Tensor(size_in, size_out))
self.b = nn.parameter.Parameter(torch.Tensor(size_out))
def forward(self, X, A):
return torch.mm(torch.mm(A, X), self.W) + self.b
A # torch.sparse.FloatTensor, size [N x N]
X # torch.FloatTensor, size [N x size_in]
A = torch.autograd.Variable(A, requires_grad=False)
X = torch.autograd.Variable(X, requires_grad=False)
# If I omit the two lines above, I get invalid argument error (torch.FloatTensor, Parameter) for torch.mm
gcn = GraphConv(X.size()[1], size_hidden)
gcn(X, A) # error here
Is there something I am doing wrong, or is this functionality simply not present in PyTorch yet?