Hi all! I’m trying to construct an ANN to decorrelate a classifier from a given feature. I think the best way to show is with a little sketch (I hope it renders):
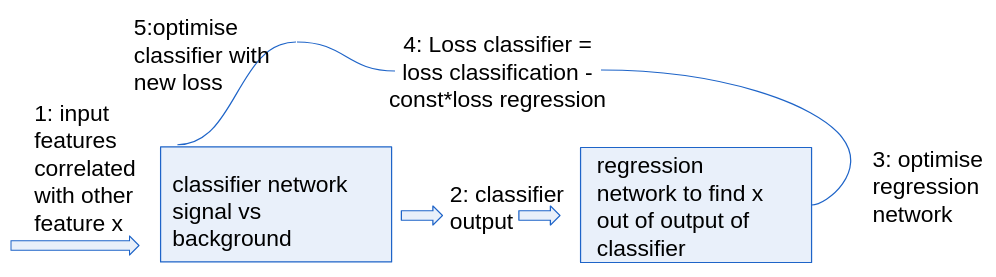
(the constant can be modified to balance classifying and feature decorellation)
The problem I have is how I pass the ANN loss to the classifier so it can calculate the gradient with respect to the classifier outputs, without modifying the ANN itself. What I have now (clearly still wrong) is something like this:
#run number of batches
for i, data in enumerate(trainloader, 0):
#regtargets are the x feature values that the regressor tries to find
inputs, targets, regtargets = data
inputs, targets, regtargets = inputs.float(), targets.float(), regtargets.float()
targets = targets.reshape((targets.shape[0], 2))
#reset optimizers
optimizer_reg.zero_grad()
optimizer.zero_grad()
#get classifier predictions
outputs = mlp(inputs)
#outputs are fed to ANN (detach, Error:args don't support auto diff, but one requires grad)
ANN_in = outputs.detach()
ANN_in.requires_grad = False
#optimise ANN to new outputs
ANN = TrainANN_hot(ANN, ANN_in, regtargets)
ANNoutputs = ANN(ANN_in)
loss_ANN = loss_function2(ANNoutputs, regtargets)
loss_ANN.backward()
optimizer_reg.step()
optimizer_reg.zero_grad()
#get new loss after optimization
ANN_in.requires_grad = True
ANNoutputs = ANN(ANN_in)
loss_ANN = loss_function2(ANNoutputs, regtargets)
#loss is calculated and complete model is retrained
loss = loss_function(outputs, targets) - lda* loss_ANN
loss.backward()
I’m new to pytorch so I hoped to get some insight on how to best implement gradient reversal.