CUDA operations are executed asynchronously, so you would have to synchronize the code before starting and stopping the timer. The torch.utils.benchmark utility provides this functionality as well as e.g. warmup iterations.
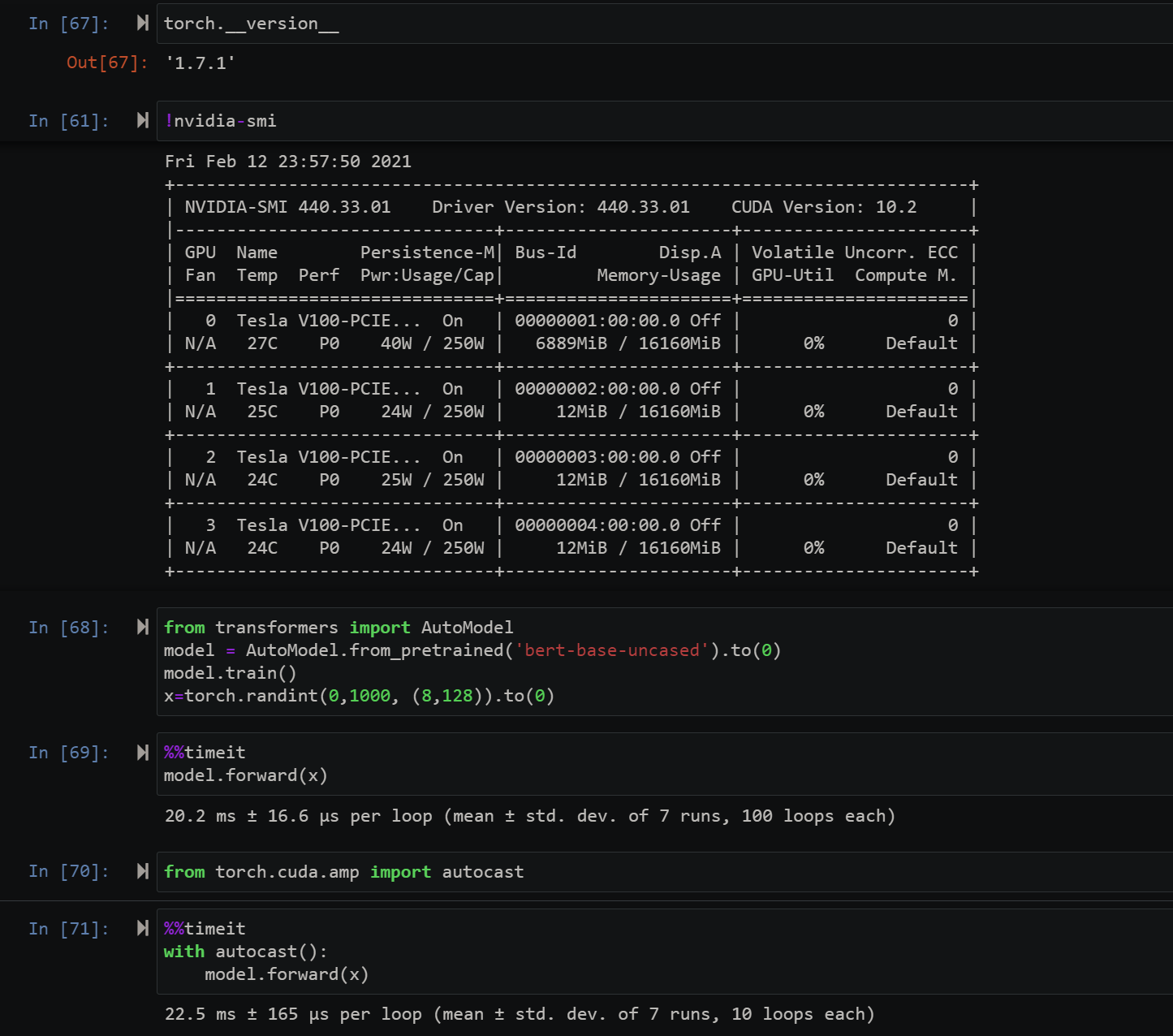
Still not seeing speed up.
import torch
from torch.cuda.amp import autocast
print(torch.__version__)
!nvidia-smi
from transformers import AutoModel
model = AutoModel.from_pretrained('bert-base-uncased').to(1)
model.train()
x=torch.randint(0,1000, (8,128)).to(1)
def autocast_forward(model, x, fp16 = False):
with autocast(enabled = fp16):
return model.forward(x)
import torch.utils.benchmark as benchmark
t0 = benchmark.Timer(
stmt='autocast_forward(model, x, False)',
setup='from __main__ import autocast_forward',
globals={'x': x, 'model':model})
t1 = benchmark.Timer(
stmt='autocast_forward(model, x, True)',
setup='from __main__ import autocast_forward',
globals={'x': x, 'model':model})
print(t0.timeit(100))
print(t1.timeit(100))
<torch.utils.benchmark.utils.common.Measurement object at 0x7f9e30ccd520>
autocast_forward(model, x, False)
19.95 ms
1 measurement, 100 runs , 1 thread
<torch.utils.benchmark.utils.common.Measurement object at 0x7f9d9fa651c0>
autocast_forward(model, x, True)
23.53 ms
1 measurement, 100 runs , 1 thread
The 15% speedup seems to be low, as the FP16 kernels are not fully saturating the GPU, which is visible in the Nsight Systems profile in the whitespaces between kernel calls. While the FP16 cublas kernels are faster, the overall speedup is lower due to this.
I don’t see 15% speedup. autocast = false is faster than autocast=true
Ah, thanks. I’ve misunderstood the timings, but saw a minor speedup on an A100 using your benchmark.
In any case, it seems the workload is heavily CPU bound. Also there are some unexpected device_to_device kernels, so I’ll look into it a bit more.
For what it’s worth - I reproed this on Tesla M60 GPU and saw the same behavior as OP - that with autocast enabled forward pass is marginally slower than without.
# fp16=True
92.23 ms
1 measurement, 100 runs , 1 thread
# fp16=False
79.00 ms
1 measurement, 100 runs , 1 thread
I also tried including backward pass, and observed the times were very similar:
model = BertForSequenceClassification.from_pretrained("bert-base-uncased").to(0)
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
inputs = tokenizer("Hello, my dog is cute", return_tensors="pt").to(0)
labels = torch.tensor([1]).unsqueeze(0).to(0)
def autocast_backward(model, inputs, labels, fp16=False):
with autocast(enabled=fp16):
outputs = model(**inputs, labels=labels)
loss = outputs.loss
loss.backward()
t0 = benchmark.Timer(
stmt="autocast_backward(model, x, False)",
setup="from __main__ import autocast_backward",
globals={"inputs": inputs, "model": model, "labels": labels,},
)
t1 = benchmark.Timer(
stmt="autocast_backward(model, x, True)",
setup="from __main__ import autocast_backward",
globals={"inputs": inputs, "model": model, "labels": labels,},
)
print(t1.timeit(100))
print(t0.timeit(100))
gave
# fp16=True
304.61 ms
1 measurement, 100 runs , 1 thread
# fp16=False
304.99 ms
1 measurement, 100 runs , 1 thread
@ptrblck any updates on the issue?
Hey @ptrblck , have you gotten a chance to look into this? Anyone working with transformers is better off using apex amp over native amp until there’s some kind of fix for this here.
Sorry for the late reply.
I’ve reran the transformer model with a source build using the latest CUDA version and see a speedup on the V100s you are using as: AMP: 16.79ms, FP32: 20.02ms, so I assume cublas might have updated their heuristics and pick faster (TC) kernels.
@aminsaied I wouldn’t expect to see a large difference between AMP and FP32 on Maxwell GPUs.
@jsleep I don’t agree, as apex/amp is deprecated and used the same autocast list in the then recommended O1 mode.
I’m having the same issue on the A6000:
import torch
from torch.cuda.amp import autocast
from transformers import AutoModel
model = AutoModel.from_pretrained('bert-base-uncased').to(1)
model.train()
x=torch.randint(0,1000, (8,128)).to(1)
def autocast_forward(model, x, fast_dtype=None):
if fast_dtype is None:
return model.forward(x)
with autocast(fast_dtype=fast_dtype):
return model.forward(x)
import torch.utils.benchmark as benchmark
t0 = benchmark.Timer(
stmt='autocast_forward(model, x)',
setup='from __main__ import autocast_forward',
globals={'x': x, 'model':model})
t1 = benchmark.Timer(
stmt='autocast_forward(model, x, fast_dtype=torch.float16)',
setup='from __main__ import autocast_forward',
globals={'x': x, 'model':model})
t2 = benchmark.Timer(
stmt='autocast_forward(model, x, fast_dtype=torch.bfloat16)',
setup='from __main__ import autocast_forward',
globals={'x': x, 'model':model})
print(t0.timeit(1000)) # prints 8.91 ms
print(t1.timeit(1000)) # prints 9.18 ms
print(t2.timeit(1000)) # prints 9.13 ms
My goal is to use bf16, not fp16, but the issue is there for both
@ptrblck is there any new insight on this?
and for backward pass:
from torch.utils import benchmark
import torch
from torch.cuda.amp import autocast
from transformers import BertForSequenceClassification, BertTokenizer
model = BertForSequenceClassification.from_pretrained("bert-base-uncased").to(0)
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
inputs = tokenizer("Hello, my dog is cute", return_tensors="pt").to(0)
labels = torch.tensor([1]).unsqueeze(0).to(0)
def autocast_backward(model, inputs, labels, fast_dtype=None):
if fast_dtype is None:
outputs = model(**inputs, labels=labels)
loss = outputs.loss
loss.backward()
return
with autocast(fast_dtype=fast_dtype):
outputs = model(**inputs, labels=labels)
loss = outputs.loss
loss.backward()
return
t0 = benchmark.Timer(
stmt="autocast_backward(model, inputs, labels)",
setup="from __main__ import autocast_backward",
globals={"inputs": inputs, "model": model, "labels": labels,},
)
t1 = benchmark.Timer(
stmt="autocast_backward(model, inputs, labels, torch.float16)",
setup="from __main__ import autocast_backward",
globals={"inputs": inputs, "model": model, "labels": labels,},
)
t2 = benchmark.Timer(
stmt="autocast_backward(model, inputs, labels, torch.bfloat16)",
setup="from __main__ import autocast_backward",
globals={"inputs": inputs, "model": model, "labels": labels,},
)
print(t0.timeit(100)) # prints 20.52
print(t1.timeit(100)) # prints 22.33
print(t2.timeit(100)) # prints 26.43 :(
Your A6000 would use TF32 by default and would thus already speedup your wokload using TensorCores. This post has additional information, but skip the “channels-last” part since you are working on a language model.
Additionally, this post discusses a similar issue and provides a profile of the workload.