I am trying to replicate something that the authors in the paper, A Closer Look at Memorization in Deep Networks, have proposed in the Section 3.2: Loss-Sensitivity in Real vs. Random Data which says:
It’s not clear from the discussion in Maclaurin et al. (2015) or their github code as to what I want to do which is essentially to backprop through training procedure.
A Digression (?): Although I am not quite familiar with Recurrent Neural Networks (RNNs) and haven’t used them in my work, I think it looks a bit similar to (but not exactly the same as) Truncated Backpropagation Through Time (TBPTT). I went through the discussion here but I am still not sure (in case it is indeed similar to TBPTT) how to implement what I need and have mentioned above. For instance, what changes would I need to make here:
# perform k1-step unrolling through the training procedure
def train(data_loader, optimizer, model):
model.train()
cnt = 0
# store the loss sensitivity values in a Tensor
loss_sensitivity = torch.zeros((len(data_loader.dataset), data_loader.tensors[0].shape[1], num_classes))
idx_last_k1 = [] # keeps track of indices of (K-k1)th batch where K is the current grad. step
for batch_id, (x,y, idx) in enumerate(data_loader):
idx_last_k1 = '''store (K-k1)th batch indices where K is the current step'''
x.requires_grad = True
if batch_id % k1 == 0:
# store the corresponding loss sensitivity values
loss_sensitivity[idx,:] = data_loader.tensors[0][idx_last_k1,:].grad.clone().detach()
# We compute gradients (for sensitivity)
# only w.r.t. the (M-k1)th batch
data_loader.tensors[0][idx_last_k1, :].detach_()
idx_last_k1 = []
...
# some more usual training operations
...
output = model(x)
loss = cce_loss(output, y)
optimizer.zero_grad()
loss.backward(retain_graph = True)
optimizer.step()
...
One thing that I realise is missing from the code snippet I have shared is that there’s no provision for storage of gradients of the form: owing to the fact that nn.Parameters are leaf Tensors because of which any operations on them won’t be traced in the computation graph.
For that, I think I will have to employ the hack needed for meta-learning wherein we need these kinds of derivatives. But even with that, I still haven’t been able to answer my question completely.
Thanks for responding to this, @albanD. However, that’s not my main concern at the moment. I wish to first understand what they really mean by unrolling the SGD steps and backpropagating through this unrolled computation graph. Can you help me understand and unpack what’s going on here?
From what I understand is that when you do regular ML, you do something like this after unrolling the training loop:
# Iteration 1
loss = f(w0)
g = grad(loss, w0)
w1 = w0 - lr * g
# Iteration 2
loss = f(w1)
g = grad(loss, w1)
w2 = w1 - lr * g
# Iteration 3
loss = f(w2)
g = grad(loss, w2)
w3 = w2 - lr * g
So you only ever backprop to the latest w value.
In this case, you can actually ask for gradients for older “versions” of w like for the loss at iteration 3, you can do grad(loss, w0). And in that case, you can see that the gradient update by SGD is actually part of the differentiable operations that the autograd need to differentiate through.
So, in that case, what I have mentioned about requiring is correct, right? In which case I either need to use higher package as you mentioned or the other hack that I mentioned above I suppose.
But other than that, does the code snippet that I have put up make sense? My main confusion is about whether or not I have used retain_graph=True correctly. So, for instance, since I want to compute the loss sensitivity every k1 steps, I am detaching the older x’s and keeping requires_grad=True only for the last k1 x’s.
It does look like what you want is very similar to truncated backpropagation through time. Only that in your case, the evaluations are not timestep but optimization steps.
You can check this post that gives an example of how to do it manually: Implementing Truncated Backpropagation Through Time - #4 by albanD
data_loader.tensors[0][idx_last_k1, :].detach_()
I am not sure what you’re trying to achieve here, but it most likely doesn’t work The indexing of [idx_last_k1, :] is returning a temporary view on the original tensor. And then you detach that temporary view inplace. But that does not modify the original Tensor!
whether or not I have used retain_graph=True correctly
You should only ever use it if you compute gradients on the same graph multiple times. Otherwise, there is something wrong.
Oh! I didn’t know that indexing like this returns a view. Then how do I detach those original Tensors? What modification do I need to make to detach only those particular x’s?
You should only ever use it if you compute gradients on the same graph multiple times. Otherwise, there is something wrong.
This is a slightly rhetorical question but let me ask it anyway: But I do need to retain the derivatives, right? I need derivatives up to k steps in the ‘past’.
Hi, @albanD, sorry for pestering you for so long, but I didn’t understand how to do the following:
How does one detach so that it modifies the original Tensor as well and not just the view?
I am talking specifically about the code snippet I have written:
# some code
...
...
data_loader.tensors[0][idx_last_k1, :].detach_()
...
...
# some code
How do I detach those particular Tensors selected by idx_last_k1specifically because as per what you said, with this code, I am only detaching the temporary views in-place and not the original Tensors. The reason why I am asking this is that I still need to be able to understand and do this even if I were to use packages for higher-order derivatives (such as higher) for computing things like .
Sorry for the delay in the answer, that thread dropped out of my unread list…
How does one detach so that it modifies the original Tensor as well and not just the view?
The detach/not detach is a property of a Tensor. So if you don’t call it on the original Tensor, it will have no effect.
You can check the thread I linked above that show how to do it.
Also note that this is not retro-active: you need to detach() (or detach_() which is just a shorthand for x = x.detach()) before using the Tensor, otherwise it won’t have any effect.
But I do need to retain the derivatives, right? I need derivatives up to k steps in the ‘past’.
If you plan to backprop in that same graph again, then yes!
But in your current code it is not clear if you were planning to do that or not so I just mentioned it as it is a common error people do.
this is not retro-active: you need to detach() (or detach_() which is just a shorthand for x = x.detach() ) before using the Tensor, otherwise it won’t have any effect.
So, now I will put my question a little differently and see if it makes sense:
How do I detach only certain indices/slices of the original Tensor. The reason why I am asking this is because I, at a given training iteration, only want to track gradient updates corresponding to the last k1 batches of inputs (x’s). So, I am interested in keeping requires_grad=True only for those inputs (x) and requires_grad=False for the rest of the inputs.

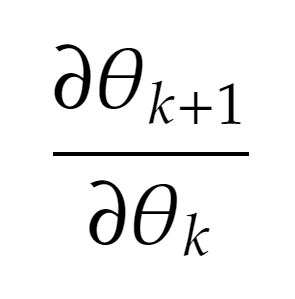 owing to the fact that
owing to the fact that  However, that’s not my main concern at the moment. I wish to first understand what they really mean by
However, that’s not my main concern at the moment. I wish to first understand what they really mean by