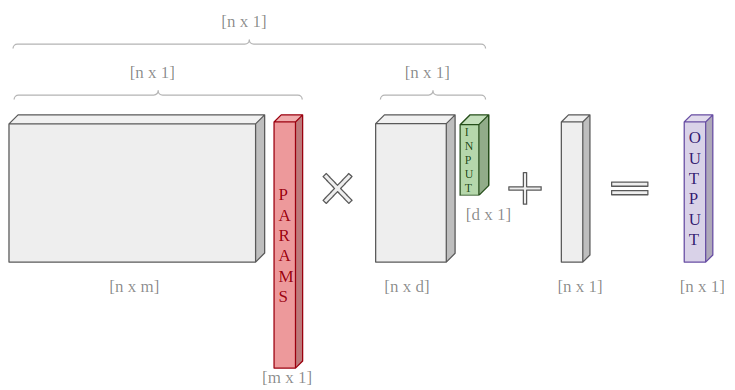
These are tensor operations between some constant tensor -in grey- and a vector of “torch.nn.Parameter(…)”, which contains the terms I want to train by gradient descent.
I created a “nn.Module” child class that implements these tensor operations in the forward method, while the constructor takes care of initialising the constant tensors and the vector of parameters.
Issue:
How can I perform/implement (mini-)batch gradient descent using the model above, considering that the forward method carries out the computations for only one input at the time?
The simplest think to do would be to make your nn.Module support batch dimension (using bmm and matmul) to replace your current version.
If you are using nightly builds, you might be able to get that automatically by using the new vmap Module. @richard will be able to help you with that if you want to go down that path
I may have solved the problem, torch seems already able to process mini-batches for this kind of computation without any further effort!
The only thing is to make sure you have in input a tensor of size [mini_batch, variable_to_optimise.shape].