Hey there,
I intend to build a densenet121-based multi-head CNN. My goal is to use the first three denseblocks as a shared set of layers and then create multiple branches using the architecture of the fourth denseblock.
My code is below:
class Densenet121_v1(nn.Module):
def __init__(self, num_classes = [1,4,2,8,3]):
super(Densenet121_v1,self).__init__()
original_model = torchvision.models.densenet121(pretrained=True)
self.num_classes=num_classes
self.trunk=original_model.features[:-2]
self.branch1=original_model.features[-2:]
self.branch2=original_model.features[-2:]
self.branch3=original_model.features[-2:]
self.branch4=original_model.features[-2:]
self.branch5=original_model.features[-2:]
#self.features=nn.Sequential(*self.trunk,*self.branch)
#self.features = nn.Sequential(*list(original_model.children())[:-1])
self.classifier1=(nn.Linear(1024, self.num_classes[0]))
self.classifier2=(nn.Linear(1024, self.num_classes[1]))
self.classifier3=(nn.Linear(1024, self.num_classes[2]))
self.classifier4=(nn.Linear(1024, self.num_classes[3]))
self.classifier5=(nn.Linear(1024, self.num_classes[4]))
def forward(self, x):
# shared trunk
trunk=self.trunk(x)
#block1:
f1 = self.branch1(trunk)
b1 = F.relu(f1, inplace=False)
b1 = F.adaptive_avg_pool2d(b1, (1, 1)).view(f1.size(0), -1)
y1 = self.classifier1(b1)
#block2:
f2 = self.branch2(trunk)
b2 = F.relu(f2, inplace=False)
b2 = F.adaptive_avg_pool2d(b2, (1, 1)).view(f2.size(0), -1)
y2 = self.classifier2(b2)
#block3:
f3 = self.branch3(trunk)
b3 = F.relu(f3, inplace=False)
b3 = F.adaptive_avg_pool2d(b3, (1, 1)).view(f3.size(0), -1)
y3 = self.classifier3(b3)
#block4:
f4 = self.branch4(trunk)
b4 = F.relu(f4, inplace=False)
b4 = F.adaptive_avg_pool2d(b4, (1, 1)).view(f4.size(0), -1)
y4 = self.classifier4(b4)
#block5:
f5 = self.branch5(trunk)
b5 = F.relu(f5, inplace=False)
b5 = F.adaptive_avg_pool2d(b5, (1, 1)).view(f5.size(0), -1)
y5 = self.classifier5(b5)
#order predictions
output= torch.cat((y1,y2[:,0:3],torch.unsqueeze(y4[:,0],1),torch.unsqueeze(y2[:,3],1),
y4[:,1:3],torch.unsqueeze(y5[:,0],1),
torch.unsqueeze(y3[:,0],1),torch.unsqueeze(y4[:,3],1),
torch.unsqueeze(y3[:,1],1),y4[:,4:7],
torch.unsqueeze(y5[:,1],1),torch.unsqueeze(y4[:,7],1),
torch.unsqueeze(y5[:,2],1)),1)
return output
model=Densenet121_v1()
out=model(torch.rand(16,3,224,224))
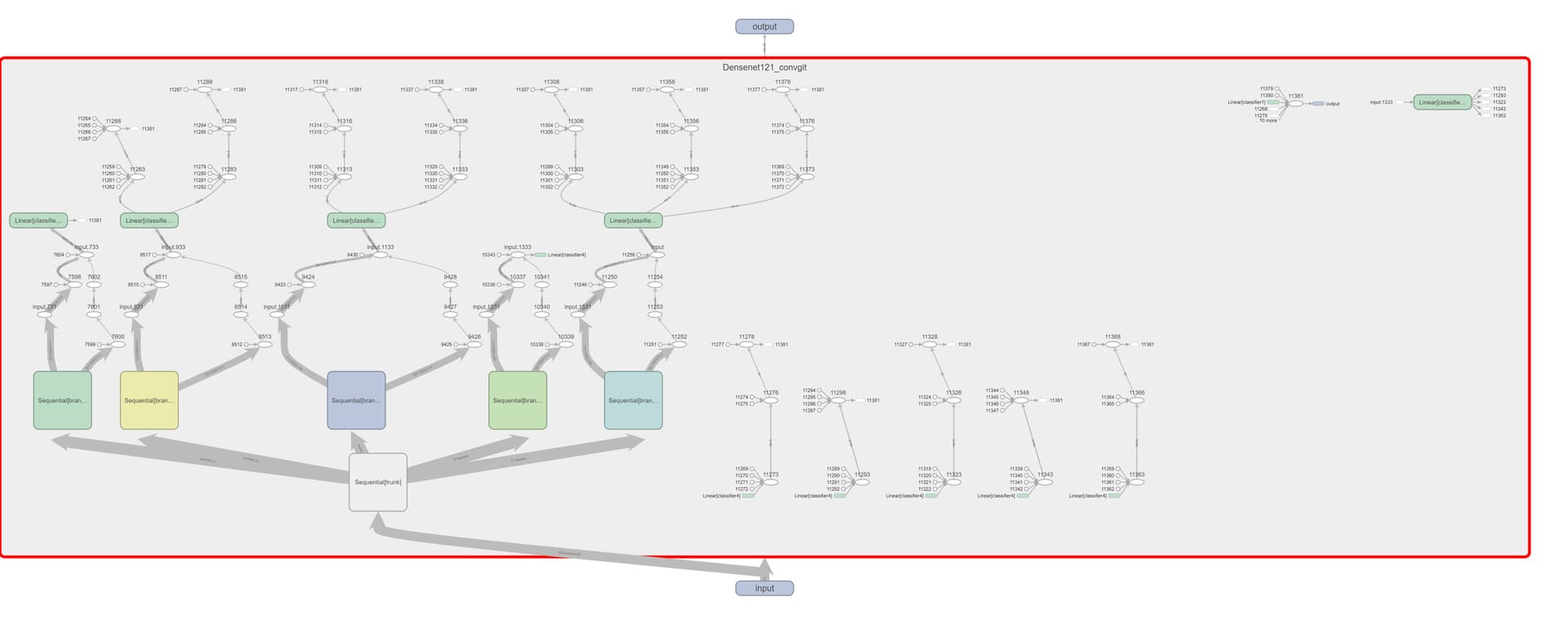
When I inspect the computational graph using tensorboard I see that some tensors resulting from batchnorm layers in branch1 are being fed into the remaining branches. This does not happen with the remaining branches:
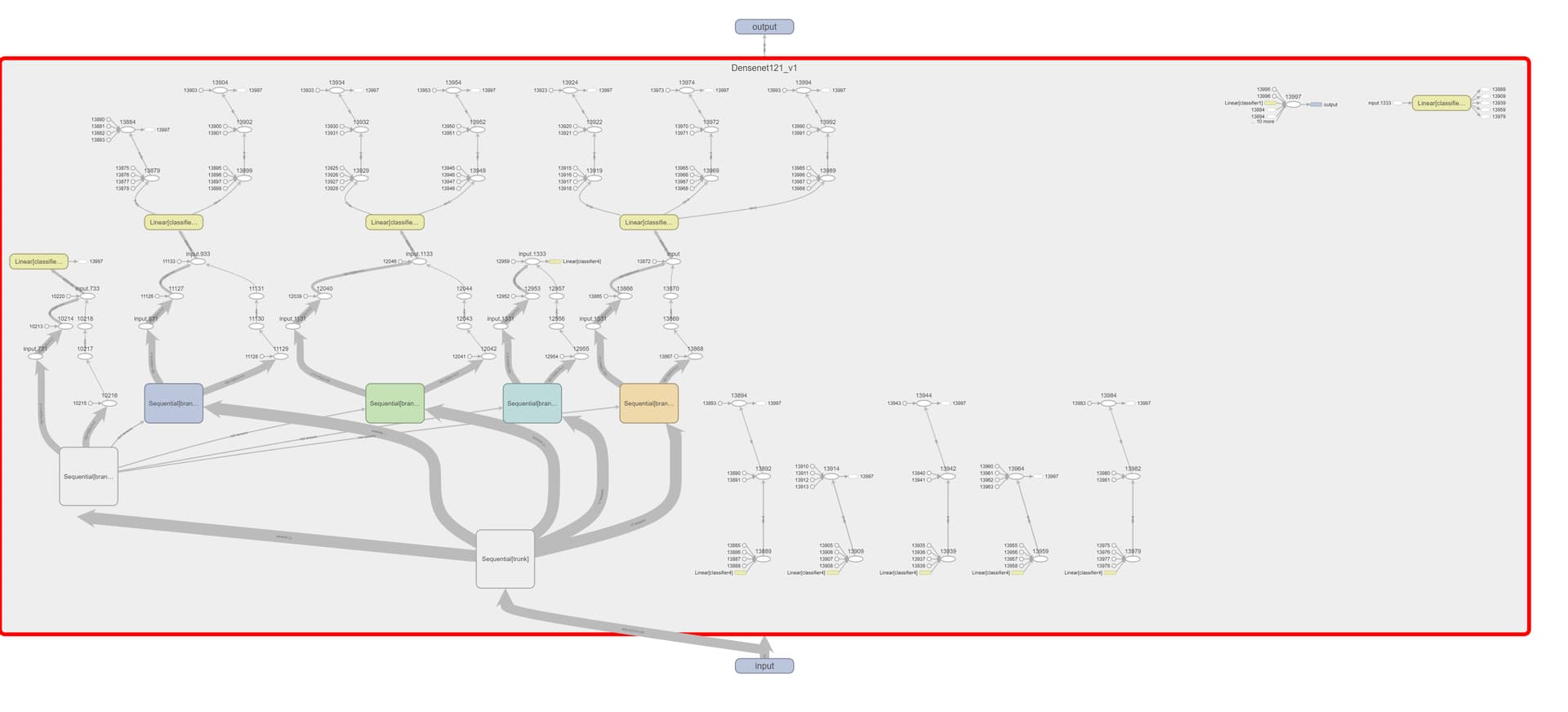
How can I avoid this? The heads should be completely independent of each other.