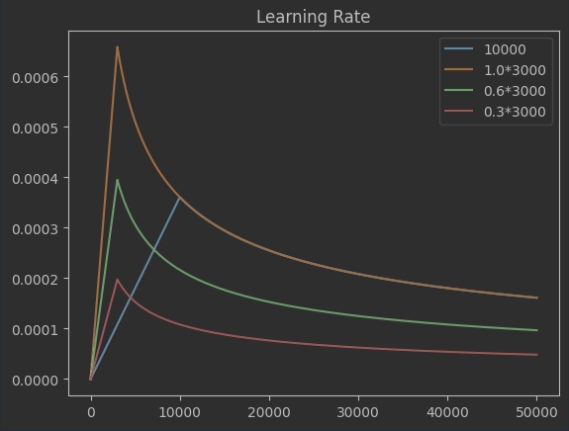
Hi K. Frank,
Yes, the last layer is nn.Linear(256, 1), and the logits are passed to BCEWithLogitsLoss().
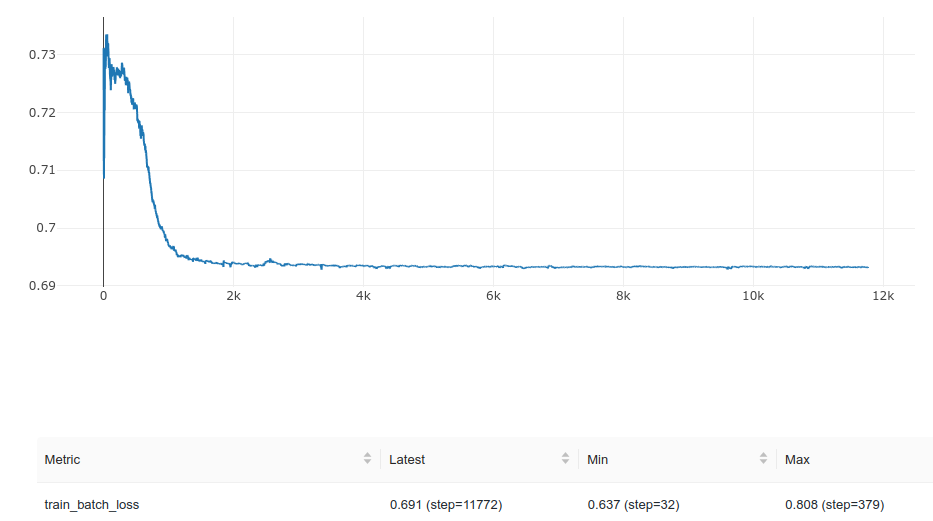
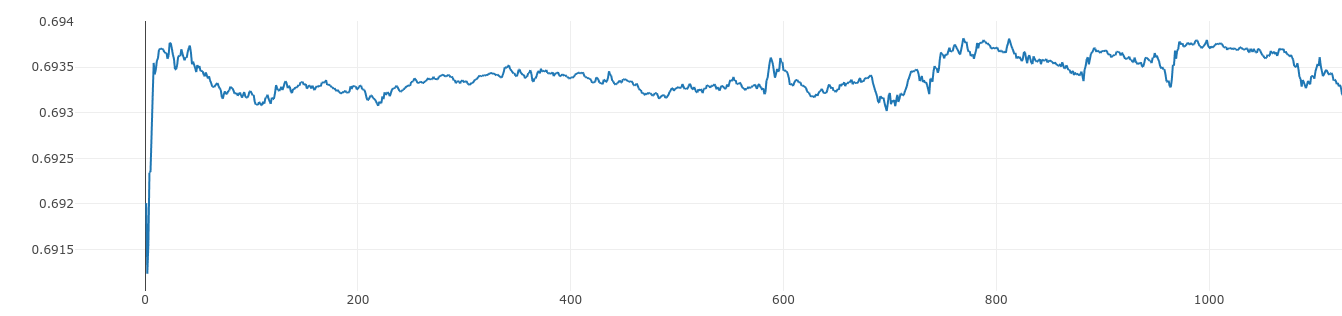
I did a few runs and for about (sometimes before and sometimes after) 5000 steps the train batch loss was fluctruating around 0.693.
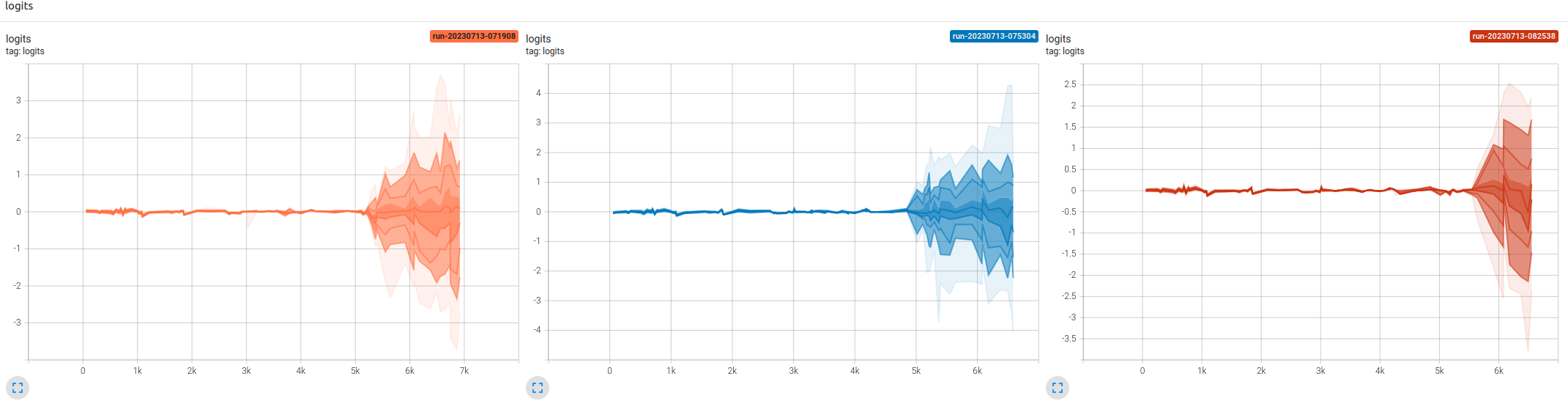
The distribution of logits in batches of 64 samples are indeed very close to 0s during these 5000 steps. It was very “narrow” distribution centered around 0. But after the initial 5000 steps, the distribution of logits started to be scattered around in a relatively larger scale. The following is for 3 runs:
During these initial 5000 steps, the BCE loss is very close to 0.693 or log(2):
run_id,key,value,step,timestamp
390b7bed44bc4cb39c5c55cfed6cbcde,train_batch_loss,0.6891335844993591,1,1689070859610
390b7bed44bc4cb39c5c55cfed6cbcde,train_batch_loss,0.6845006346702576,2,1689070859728
390b7bed44bc4cb39c5c55cfed6cbcde,train_batch_loss,0.6913905143737793,3,1689070859858
390b7bed44bc4cb39c5c55cfed6cbcde,train_batch_loss,0.693462610244751,4,1689070859981
390b7bed44bc4cb39c5c55cfed6cbcde,train_batch_loss,0.6899896264076233,5,1689070860125
390b7bed44bc4cb39c5c55cfed6cbcde,train_batch_loss,0.697765588760376,6,1689070860260
390b7bed44bc4cb39c5c55cfed6cbcde,train_batch_loss,0.7007498145103455,7,1689070860400
390b7bed44bc4cb39c5c55cfed6cbcde,train_batch_loss,0.7083665132522583,8,1689070860508
390b7bed44bc4cb39c5c55cfed6cbcde,train_batch_loss,0.6904076933860779,9,1689070860619
390b7bed44bc4cb39c5c55cfed6cbcde,train_batch_loss,0.6960662603378296,10,1689070860750
390b7bed44bc4cb39c5c55cfed6cbcde,train_batch_loss,0.7000266909599304,11,1689070860854
390b7bed44bc4cb39c5c55cfed6cbcde,train_batch_loss,0.6916379928588867,12,1689070860984
390b7bed44bc4cb39c5c55cfed6cbcde,train_batch_loss,0.7038472294807434,13,1689070861120
390b7bed44bc4cb39c5c55cfed6cbcde,train_batch_loss,0.695785403251648,14,1689070861232
390b7bed44bc4cb39c5c55cfed6cbcde,train_batch_loss,0.6908349990844727,15,1689070861331
...
...
390b7bed44bc4cb39c5c55cfed6cbcde,train_batch_loss,0.6938340663909912,5298,1689071557099
390b7bed44bc4cb39c5c55cfed6cbcde,train_batch_loss,0.6932273507118225,5299,1689071557211
390b7bed44bc4cb39c5c55cfed6cbcde,train_batch_loss,0.6899099946022034,5300,1689071557334
390b7bed44bc4cb39c5c55cfed6cbcde,train_batch_loss,0.6955896019935608,5301,1689071557467
390b7bed44bc4cb39c5c55cfed6cbcde,train_batch_loss,0.6937833428382874,5302,1689071557567
390b7bed44bc4cb39c5c55cfed6cbcde,train_batch_loss,0.6919088363647461,5303,1689071557679
390b7bed44bc4cb39c5c55cfed6cbcde,train_batch_loss,0.6920832395553589,5304,1689071557783
390b7bed44bc4cb39c5c55cfed6cbcde,train_batch_loss,0.6949018239974976,5305,1689071557898
390b7bed44bc4cb39c5c55cfed6cbcde,train_batch_loss,0.6921497583389282,5306,1689071558024
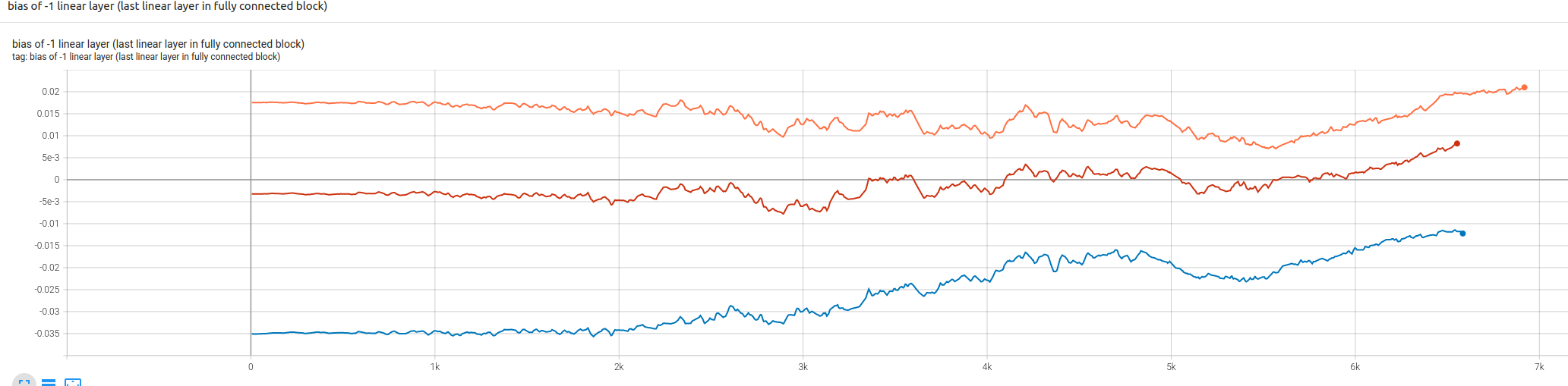
The bias of last layer (Linear (256, 1)) seems to be pulled towards 0 in the beginning 5000 steps, regardless of the initialized value being positive or negative:
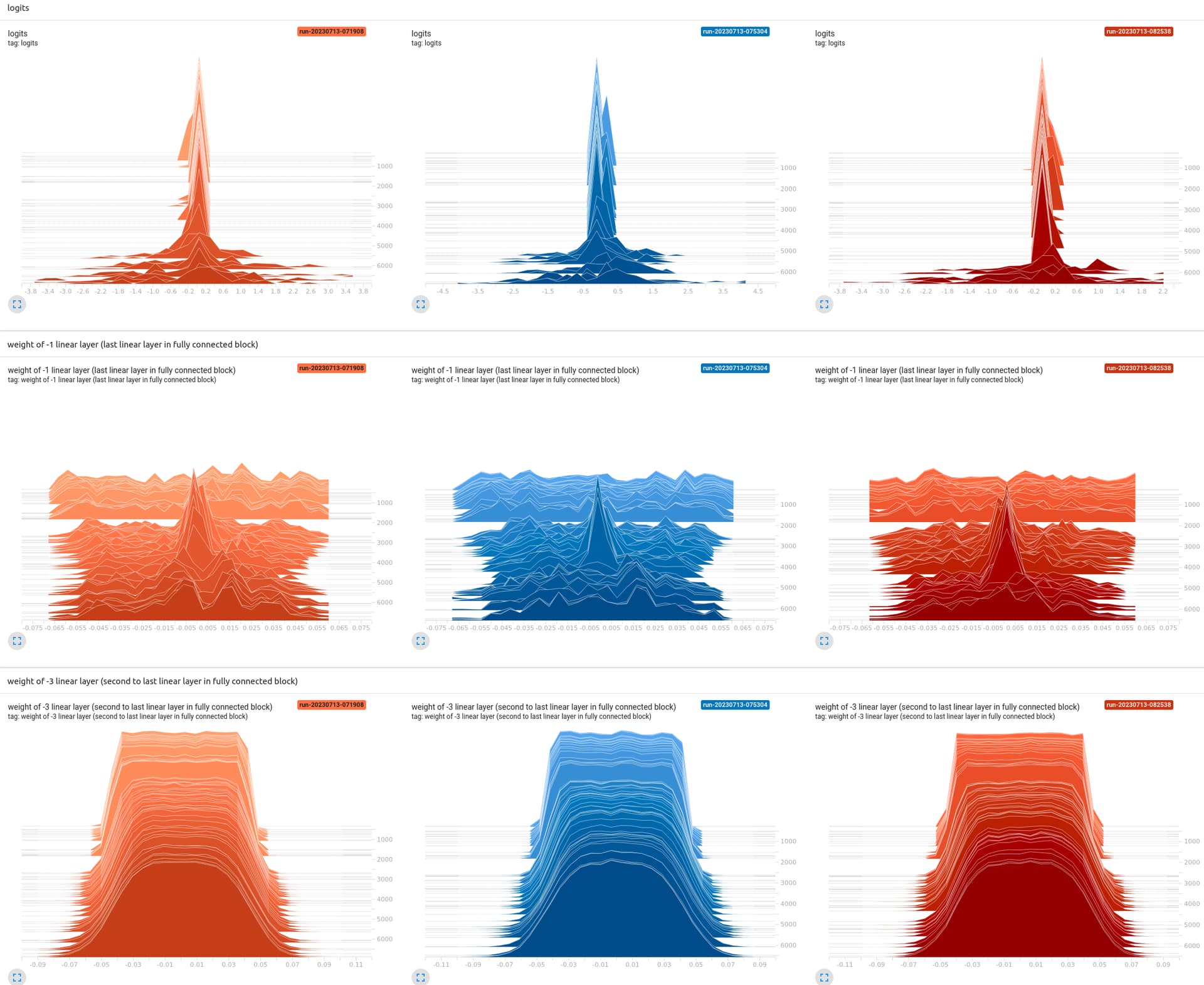
I’ve also plotted the histgrams of the weights of the last and the second to the last linear layers. It looks the distribution of weight of the linear layers before the last linear layer didn’t change much during the first 5000 steps. If the distribution of weight does not change much, maybe the speicifc values are not changing much then.
The following is the part related to loss criterion. I used DDP for running the model, but actually I’m running it on my local PC with a single GPU.
self.ddp_model = DDP(model, device_ids=[gpu_id], find_unused_parameters=True) # False
...
self.criterion = nn.BCEWithLogitsLoss(reduction='mean') # batch loss mean
...
for train_batch in self.train_dataloader:
train_batch_step += 1
self.optimizer.zero_grad()
output = self.ddp_model(**get_features(train_batch, self.gpu_id))
train_batch_loss = self.criterion(output, get_label(train_batch, self.gpu_id))
train_batch_loss.backward()
self.optimizer.step()
self.lr_scheduler.step()