when I am using DataParallel, I notice that it only works when the data is on the first available cuda device.
Say I am doing something like
for batch_idx, (features, targets) in enumerate(train_loader):
features = features.to(device)
targets = targets.to(device)
If device is “cuda:1” it throws an error RuntimeError: all tensors must be on devices[0]. However, if I change the device to “cuda:0” the parallel training on multiple GPUs works just fine.
How are you setting your cuda device ? What Gpus are you using ?
In general to distribute equally to all your GPUs you need to pass “cuda”. By passing “cuda:0” it will only use the GPU 0 not all of them.
On the past I had a GTX 690 (DUAL CORE GPU already in SLI) that only was controlled by the GPU:0 even NVIDIA developers told me that was a bug on the driver. But never fixed.
Could you post the code part where your model is wrapped into DataParallel?
As far as I know, you have to push the data onto the “default” device, i.e. the GPU where the scatter and gather will take place. If there is a mismatch, this error is thrown.
In general to distribute equally to all your GPUs you need to pass “cuda”. By passing “cuda:0” it will only use the GPU 0 not all of them.
of course. this was just for the dataset. Let be paste a bit more code for the context
Could you post the code part where your model is wrapped into DataParallel ?
device = torch.device("cuda:0")
...
model = VGG16(num_features=num_features, num_classes=num_classes)
if torch.cuda.device_count() > 1:
print("Using", torch.cuda.device_count(), "GPUs")
model = nn.DataParallel(model)
model.to(device)
...
for epoch in range(num_epochs):
model.train()
for batch_idx, (features, targets) in enumerate(train_loader):
features = features.to(device)
targets = targets.to(device)
In this case, it’s 4 GPUs, and the whole things seems to work; I get even 3x speed-up compared to the 1 GPU version without DataParallel. It’s also utilizing the default GPU 99% and the others ~95%. It only works if "cuda:0" for the device, not "cuda:1" (with cuda devices 0, 1, 2, 3 available; if it’s weird why I am asking for that: I have left the monitor plugged in into the cuda:0 device, and since it’s weekend, I am working from home :P).
By passing “cuda:0” it will only use the GPU 0 not all of them.
I think if "cuda:0" is your default/current device, the shouldn’t be a difference between torch.device("cuda") and torch.device("cuda:0") according to the docs at Tensor Attributes — PyTorch 2.1 documentation
The parallelism (using all GPUs) is basically achieved via model = nn.DataParallel(model) where it uses all GPUs by default, except you specify only a subset via the device_ids argument of DataParallel).
What Gpus are you using ?
that would be 4 GeForce 1080Tis. They are all the same, but maybe there’s sth weird about the first device regarding the drivers like you said …
device = ("cuda" if torch.cuda.is_available() else "cpu" )
model = net()
if torch.cuda.device_count() > 1:
# device_ids has a default : all
model = torch.nn.DataParallel(model, device_ids=[0, 1, 2, 3])
model.to(device)
Thanks, I tried that, but then it is still using the cuda:0 device for the data gathering, because on my setup, your example would be equivalent to
device = ("cuda:0" if torch.cuda.is_available() else "cpu" )
model = net()
if torch.cuda.device_count() > 1:
# device_ids has a default : all
model = torch.nn.DataParallel(model, device_ids=[0, 1, 2, 3])
model.to(device)
(PS: It’s correctly utilizing all 4 GPUs based on what I can see via nvidia-smi, but the gradient averaging etc. is carried out on the first card)
however, I want to use "cuda:1" (or 2, or 3) for the data gathering instead of the 1st device. It’s not super important to me, since I can simply plug in the monitor into a different card, but the discussion is also to see whether there’s a bug in PyTorch.
Then you can try this…
Letting device = “cuda” is generic in case of the pure model setting the first one GPU or in case of DataParallel you need send the exact ids you want or just omit it to get them all
device = ("cuda" if torch.cuda.is_available() else "cpu" )
model = net()
if torch.cuda.device_count() > 1:
# device_ids has a default : all
model = torch.nn.DataParallel(model, device_ids=[1,2])
model.to(device)
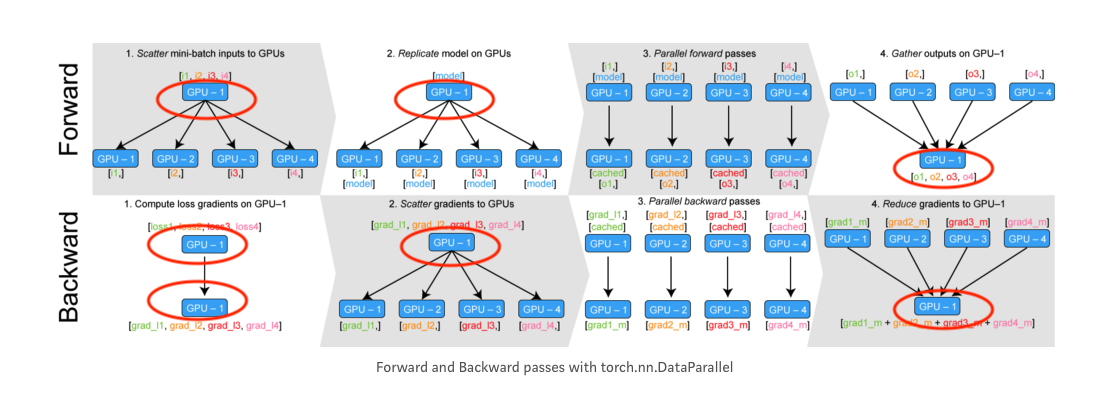
Basically, in the ones that I circled, I want this to be e.g., GPU-2 not GPU-1. Theoretically, this should be possible by just setting device=torch.device('cuda:1')
and then using
.to(device) for the model and the data tensors.
As well as the output_device=device inside DataParallel
PS: I am using PyTorch 0.4.1, that’s the most recent one I think (except for the release candidates)
If you have time you can build it or try to use the nightly build to try it. I believe is on the official web site. If not you still can build it. It will take a few hours depending of memory and cores on CPU … but you can try.
Yeah. But I probably will wait a bit since I currently have a well working custom compiled version of the stable one. It’s kind of a bit of work for me so I will wait until the next release comes out. This feature is not so urgent for me personally, but I suspected that there might be a bug in the PyTorch implementation when using DataParallel, because according to the docs, changing the default device (like the ones circled in the figure) should be possible.
What if you say device_ids=[1, 2, 3,0] in nn.DataParallel?
Ha! This solves the issue! So when I define
device = torch.device("cuda:1")
for
model.to(device)
(and the data tensors) it breaks when I leave the defaults in DataParallel or have sth like device_ids=[0, 1, 2, 3] in DataParallel but if I then change it to device_ids=[1, 2, 3, 0] it works. Just wondering if this is intended or a bug. @smth
makes sense then though. Just feel like it should be in the docs then. Happy to send a PR with an “explanation” if that’s indeed just a misunderstanding

 IMHO it is intended to be this way.
IMHO it is intended to be this way.