Isn’t that related to what we’ve discussed in Bug in DataParallel? Only works if the dataset device is cuda:0 - #12 by rasbt? I.e., that the results are intermittently gathered on one of the devices?
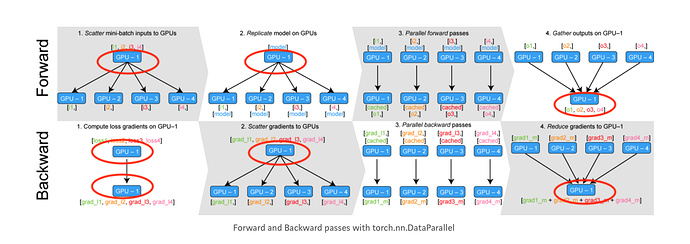
If the batch size is larger, there will be more stuff to be gathered, which is what could explain why the difference is more pronounced if you increase the batch size.