I am thinking about doing a 1d convolution over token embeddings matrix (over time dimension) and then just max pool it. After max pooling, sequences of any length will become a vector of fixed length. So I want my learning and inference steps both to be able to take sequences o any length.
Is it possible to do in Pytorch? I mean I know it is possible, but I am trying to figure out the best way to do it. Have somebody tried it yet?
I’m unsure if you are asking about the pooling operation creating the outputs in a fixed size, but it so you could use nn.AdaptiveMaxPool2d and define the desired output size.
Thank you, this will definitely help! Should I just use Python build ins like lists/tuples to represent a batch of sentences of varied length? Will it slow the training down significantly?
Different sample sizes in a single batch won’t work out of the box and the common approach would be to either pad them to the longest sequence in the batch or to use the experimental NestedTensor support.
Note that the latter is used in some internal transformer layers, but I don’t know how well other modules are supported. @vdw also provided an approach here where samples with the same length are sampled into a single batch to avoid padding in case that’s interesting for your use case.
As @ptrblck said, within a batch you need to ensure that all sequence have the same length, either through padding or through some smarter organization (cf. linked post).
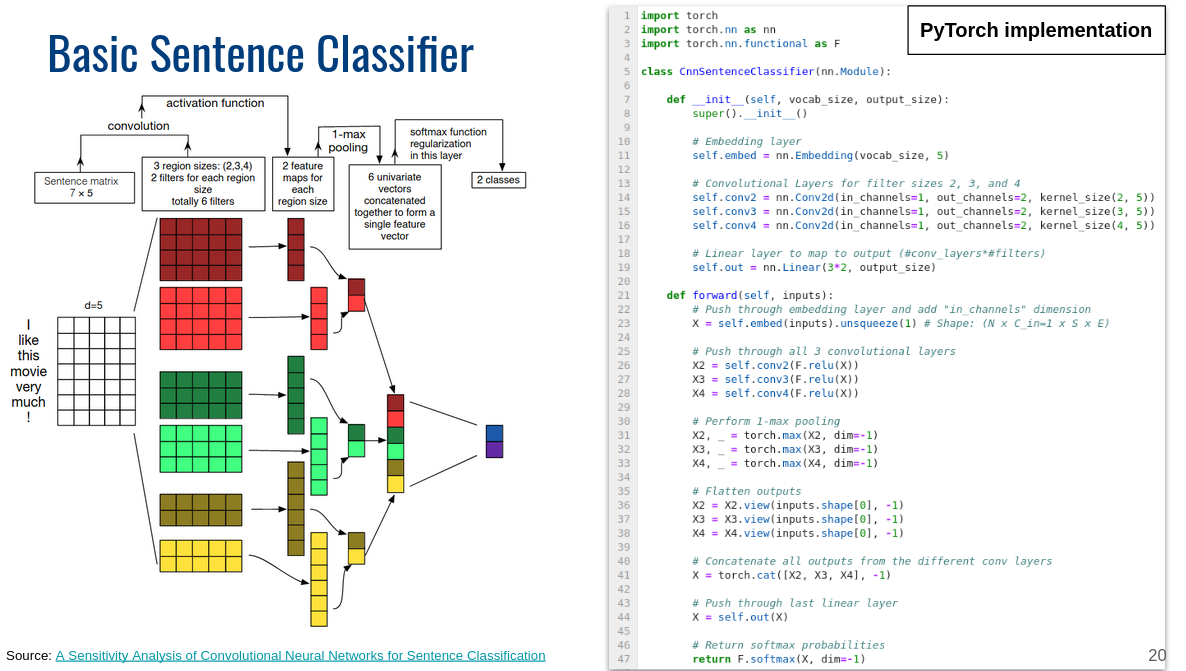
This is not correct for standard max pooling. As max pooling basically also just slides a window over you vector and aggregates the values within that window. The longer your sequence, the more sliding, the more output values. See this slide:
In this case, yes, different batches wit different sequence length would result in the same outputs, and you wouldn’t need to worry the dimensions of subsequent layers. For example, when you search on Google for text classification with CNNs, you very likely stumble on this architecture:
Thank you my friend! Yes, I do 1-Max pooling, but without standardizing the input sequence length it’s still a bit problematic to implement. The easy choice is to standardize lengths using padding, so I decided to stick to it for now, instead of using something like NestedTensor