I have an input tensor of shape (2,3,5). The 3 is the channel dimension. If I need to perform convolution (1D and 2D both) channel-wise ( each channel should have different weights and biases) using Pytorch.
Let’s say the output channel dim of the conv is 10 and kernal size is 3 for 1D conv, then i should have an output tensor with shape (2,3x10,5). Each input channel should have an output channel dim as 10 separately.
Can i implement it in such a way using Pytorch?
Please give me an example code.
Thank you very much, @ptrblck . So in this case, kernels are groped for each channel. Then is these kernels selected randomly or it is unique for every epoch in training?
I’m not sure I understand the question correctly, but the parameters are randomly initialized once during the layer creation and trained afterwards. Re-initializing parameters in each epoch would reset the training.
Each time your data goes through, it gets processed by all of the kernels. In this case, the order will make a difference since you are grouping them. I.e. the kernels applied the “Red” channel (index 0) will always be the same.
sorry for the confusion @ptrblck . I mean the selection of kernels for each group is same for all the time?
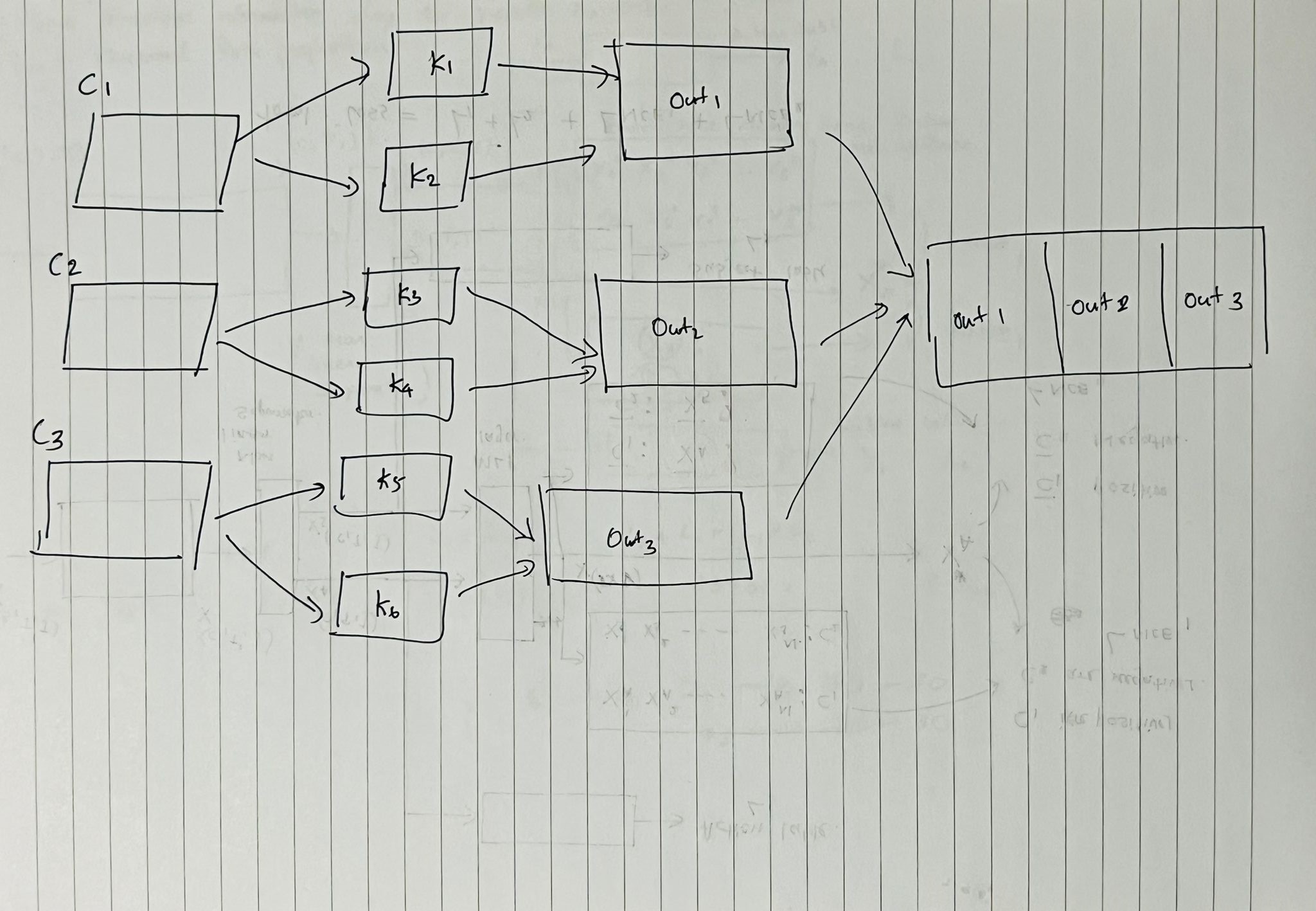
here is a graphical drawing that i need to do. lets take i have 3 channels and each channel needs to process separately. So by groping k1, k2 allocates to channel 1 and so on. I doubt that k1,k2 are always allocated to channel 1 or can it be changed in each epoch?
Thank you very much for your explanation @J_Johnson. i think this is the answer i expected but can you confirm it by looking at the figure i attached to this thread ?
Thanks for clarifying. @J_Johnson is right and the order will be the same. Shuffling the kernels would also break the training. This post visualizes the processing and also links to another code snippet verifying the results.
Thank you, @ptrblck; the link helps me to understand the case.
I have another problem. let’s take my input as X in shape ( N, C, T, V). N is batch size, C is channels, T frames, V points. So if I need to encode a single for a given channel c1 for a given point v1 using a 1D conv network, i have to select X[:,c1,T,v1]. Lets assume that the 1D network is shared and to encoder the signals for every point and every channel i have to use for loops as
class EnCo1D(nn.Conv1d):
def __init__(self, *args, **kwargs):
super(EnCo1D, self).__init__(*args, **kwargs)
def forward(self, x, squeeze=False):
# x: N x C x L
if x.dim() not in [2, 3]:
raise RuntimeError("{} accept 2/3D tensor as input".format(
self.__name__))
x = super().forward(x if x.dim() == 3 else torch.unsqueeze(x, 1))
if squeeze:
x = torch.squeeze(x)
return x
for channel in range (0,x.shape[1]):
for points in range (0,x.shape[3]):
s = EnCo1D(x[:,channel ,:,points ])
Here the network is a encoding network which has a 1D conv blocks. Although my target is accomplished I felt that the code i used is not optimised. So can you help me to implement this one in much professional manner ?