Hello everyone ![]()
Currently, I have a model trained on Pytorch. Its size is around 42 Mb. The expected inputs of this model are (1, 3, 512, 512) images. This model should be deployed on an iOS mobile app but first it needs optimization. I found out about Eager Mode Quantization as a method used in Pytorch so I am using post-training static quantization to optimize my model.
Once the quantization applied to this model, I obtain a quantized model that is around 11Mb and I can se that my layers have been quantized such as follows:
(quant): Quantize(scale=tensor([1.]), zero_point=tensor([0]), dtype=torch.quint8)
(conv1): QuantizedConv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), scale=1.0, zero_point=0, padding=(1, 1), bias=False)
(bn1): QuantizedBatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): QuantizedConv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), scale=1.0, zero_point=0, padding=(1, 1), bias=False)
(bn2): QuantizedBatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(dequant): DeQuantize()
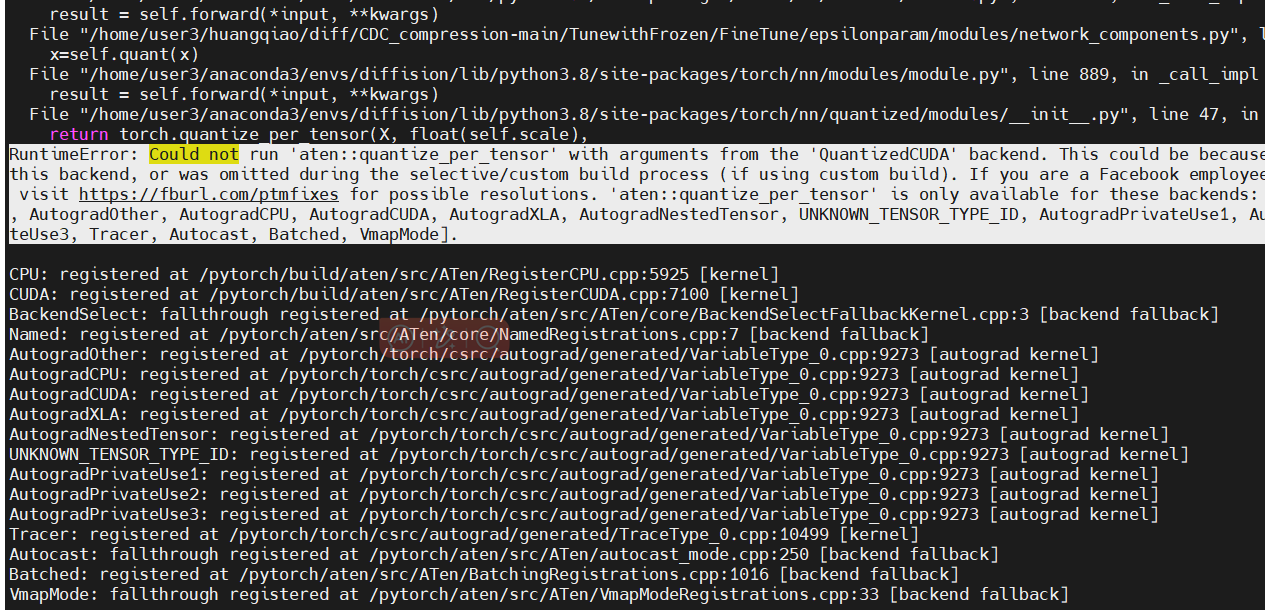
However, when I try to make an inference on a random image, I obtain this error NotImplementedError: Could not run 'aten::quantize_per_tensor' with arguments from the 'QuantizedCPU' backend.
Here is the code when I do the inference on a random image:
from quant_architecture import *
import torch.nn.functional as F
import numpy as np
# --- Test quantized model on input
model_q = ResNet(resnet18_config, 2)
model_q.eval()
model_q.to("cpu")
backend = "fbgemm" # x86 machine
model_q.qconfig = torch.quantization.get_default_qconfig(backend)
model_static_prepared = torch.quantization.prepare(model_q, inplace=False)
model_static_quantized = torch.quantization.convert(
model_static_prepared, inplace=False
)
model_static_quantized.load_state_dict(torch.load("focus_quantized_test.pt"))
model_static_quantized.to("cpu")
# # # # --- Test output on quantized model
np.random.seed(44)
dummy_input = torch.rand(1, 3, 512, 512).to("cpu", dtype=torch.float) # Corresponds to a 512*512 RGB image
test_output, hidden = model_static_quantized(dummy_input)
unscripted_top2 = F.softmax(test_output, dim=1).topk(2).indices
print('Python model top 2 results:\n {}'.format(unscripted_top2))
Here is the quantization code applied to my original model:
from quant_architecture import *
import os
# --- Create architecture focus model with Quant()/DeQuant()
# Create a model instance
model = ResNet(resnet18_config, 2)
# Load weights from trained model
model.load_state_dict(torch.load("focus_weights.pt"))
print("%.2f MB" % (os.path.getsize("focus_weights.pt") / 1e6))
# Display model
print("Initial model looks like:\n", model)
# --- Quantization of initial model with Quant()/DeQuant() architecture
model.eval() # useful for calibration
backend = "fbgemm" # x86 machine
model.qconfig = torch.quantization.get_default_qconfig(backend)
# print(model.qconfig)
model_static_prepared = torch.quantization.prepare(model, inplace=False)
model_static_quantized = torch.quantization.convert(
model_static_prepared, inplace=False
)
# Display quantized model
print("Quantized model looks like:\n", model_static_quantized)
# --- Save quantized model before C++ interface
torch.save(
model_static_quantized.state_dict(), "focus_quantized_test.pt"
) # Save unscripted quantized model - test
# Display size of quantized model
print("%.2f MB" % (os.path.getsize("focus_quantized_test.pt") / 1e6))
Additional info:
In my script quant_architecture, I added self.quant = torch.quantization.QuantStub() & self.dequant = torch.quantization.DeQuantStub() around my original model. Also, I added x = self.quant(x) & x = self.dequant(x) in the froward function.
Besides, I added input.to("cpu", dtype=torch.float) and model_static_quantized.to("cpu") to make sure that the inference is running on CPU and not QuantizedCPU.
Seems that issue comes from around here: pytorch/native_functions.yaml at 6cbe9d1f58fdc9288833b8d82db6896af0e4555f · pytorch/pytorch · GitHub
Any suggestions, ideas or questions would help a lot!
Thanks ![]()