Is there some way to reduce the CPU memory allocation on init of torch?
When we run torch.is_available() it allocates 11GB for one GPU and 44.2GB when we use six GPUs.
Then when we start the workers in the training loop that CPU allocation is copied to each worker, so we see this massive memory use.
The 11GB is much bigger than the model + n x workers * batch size we roughly expect things to be.
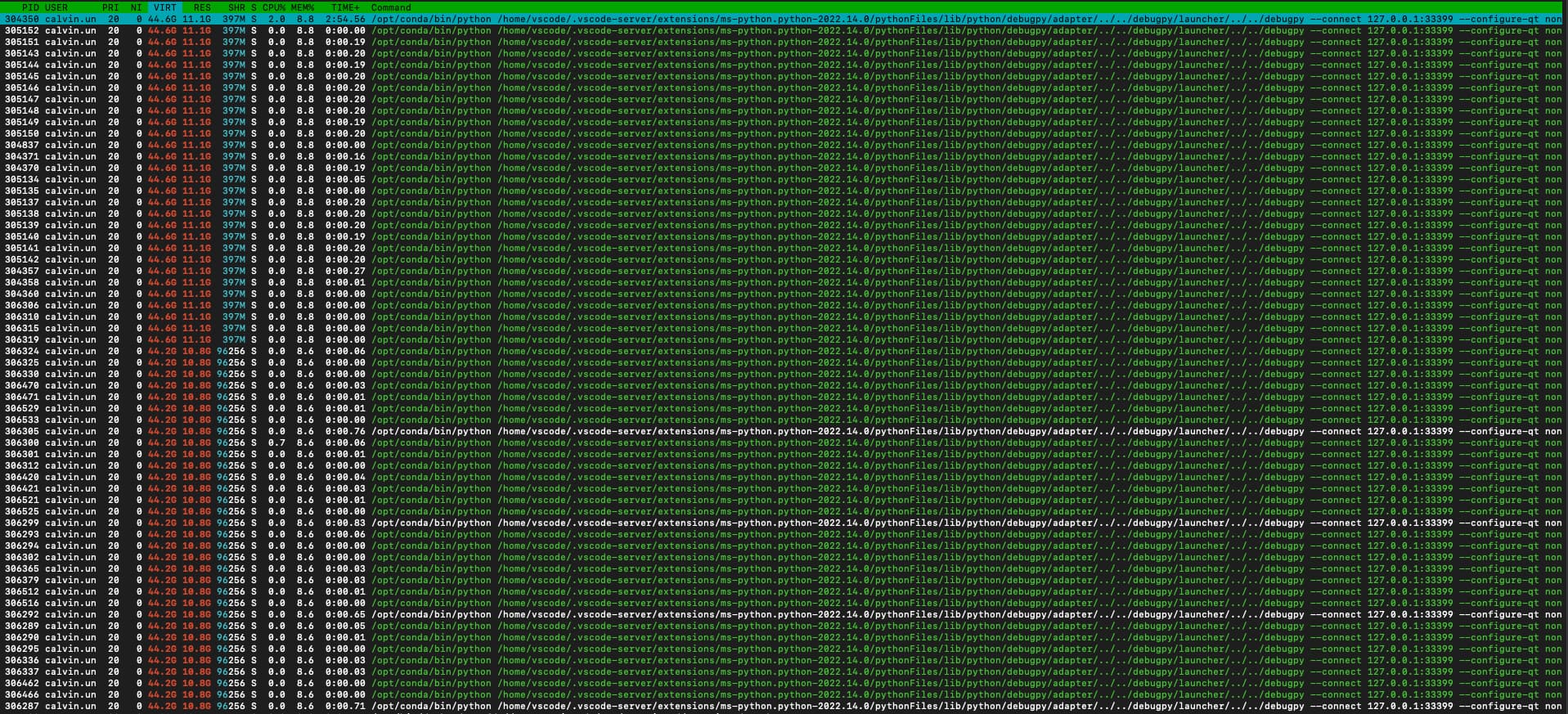
Sorry if this is dead obvious but we found 3 open issues on this and no obvious smoking gun of what we might be doing wrong or is 11GB of CPU memory the expected overhead of using a GPU?
Thanks,
Ric
P.S. Some small technical details.
Using the current Nvidia Docker image for Pytorch
(FROM nvcr.io/nvidia/pytorch:22.08-py3)
Model and Training loop is Detectron2 Masked RCNN