I am sure that this topic might have been discussed many times, but none of the proposed solutions work for me.
I was running my model, and then I had to interrupt the execution to do some modifications and rerun it. However, when I do so, I get the following error message:
RuntimeError: CUDA out of memory. Tried to allocate 2.67 GiB (GPU 0; 23.65 GiB total capacity; 6.30 GiB already allocated; 363.19 MiB free; 6.46 GiB reserved in total by PyTorch).
My model is small, so I am sure this is not a problem of fitting a large model into a smaller GPU memory. In fact, it was running before I interrupted its execution
I have tried all of the following, but none of them are working:
1- Restarting the kernal.
2- using torch.cuda.empty_cache(). before/after restarting the kernal.
3- Cheking the allocated meoery by: print(torch.cuda.memory_allocated()) and getting that it is zero.
4 - The “nvidia-smi” shows that 67% of the GPU memory is allocated, but doesn’t show what allocates it. In fact, when you sum the individual GPU memory usage of the processes, they don’t add up to that total memory usage. The individuals processes use 1% of the total GPU memory.
The only thing that will work is if I restart my PC. But even after that, if I run the model and then terminate it, the out-of-memory issue will appear again.
Edit (1): Below is my GPU status
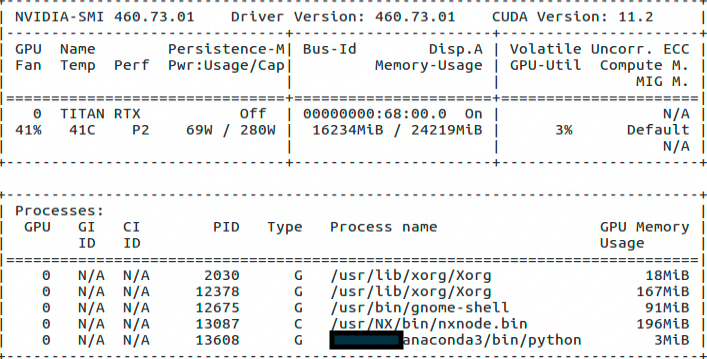
Edit (2): Found this discussion PyTorch doesn't free GPU's memory of it gets aborted due to out-of-memory error by @my3bikaht and used killall python through the terminal which solved my issue.
But I still find it weird as I am not using multithreading ( and don’t have child processes) in my model.
In fact, I was terminating exactly the same code and restarting it normally before, and then suddenly this issue started to happen.