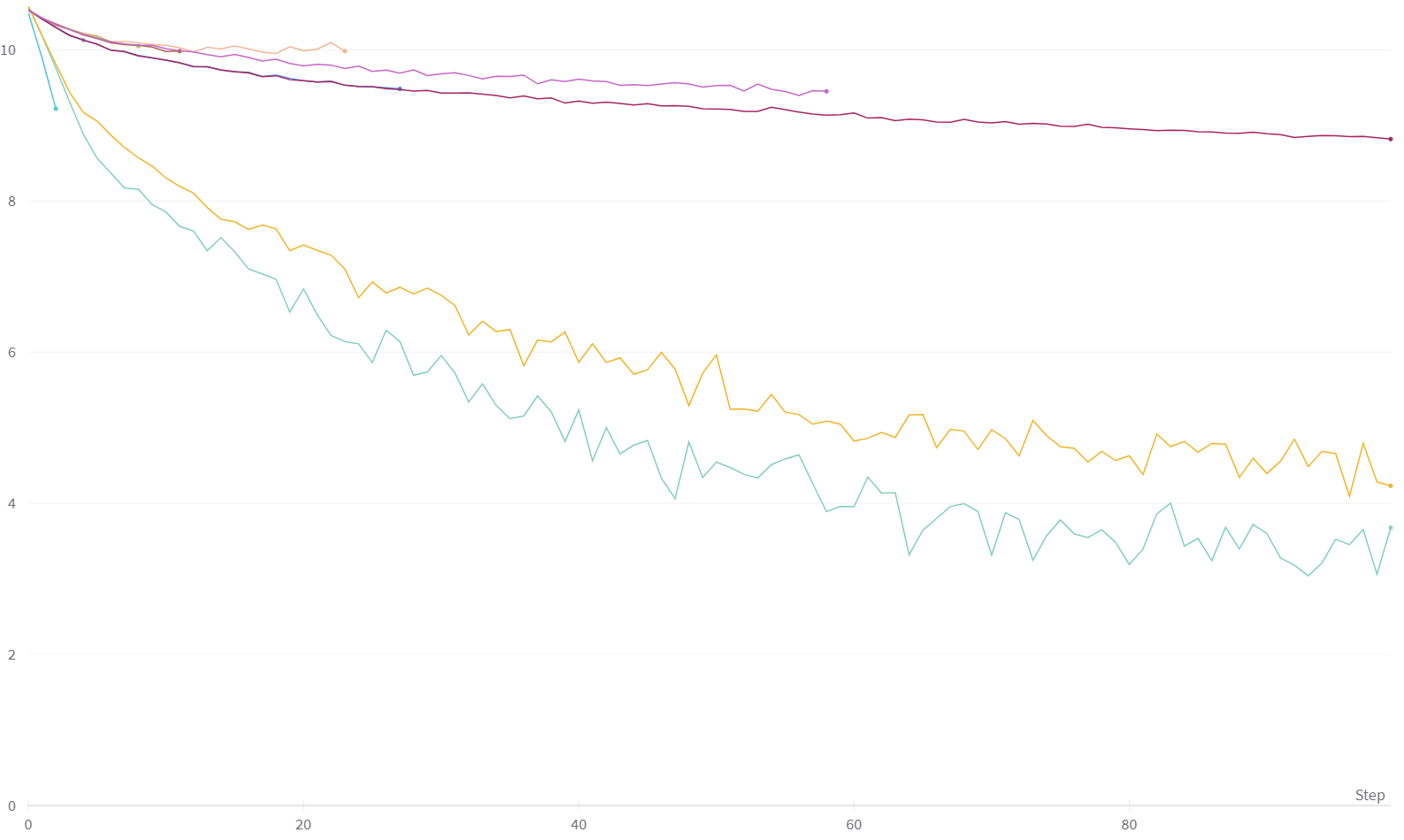
Basically the same issue as the one described in the above thread, where the results for training and evaluation are much better when using a single GPU than when using multiple GPUs.
The only changes i make when using DDP are initializing the distributed processes, wrapping the model in DDP, and using the DistributedSampler for training, and then using the sampler to set the epoch during training :
if 'WORLD_SIZE' in os.environ:
args.local_rank = int(os.environ['LOCAL_RANK'])
args.distributed = int(os.environ['WORLD_SIZE']) > 1
if args.distributed:
args.device = 'cuda:%d' % args.local_rank
torch.cuda.set_device(args.local_rank)
torch.distributed.init_process_group(backend='nccl', init_method='env://')
args.world_size = torch.distributed.get_world_size()
args.rank = torch.distributed.get_rank()
sampler = data.DistributedSampler(ds, num_replicas=args.world_size, rank=args.rank, shuffle=True,
drop_last=True)
data_loader = data.DataLoader(ds, batch_size=args.batch_size, num_workers=args.cpu_workers,
pin_memory=args.pin_memory, sampler=sampler)
model = DDP(model, device_ids=[args.local_rank], output_device=args.local_rank)
if self.args.distributed:
self.train_loader.sampler.set_epoch(self.epoch)
if self.args.distributed:
# this is taken from https://github.com/rwightman/pytorch-image-models/blob/master/timm/utils/distributed.py
distribute_bn(self.model, self.args.world_size, True)
Asides from that mostly everything else is the same (I wrapped print statements so that they only print in local_rank == 0, but asides from that it’s the same). Validation is done using SequentialSampler and only done in local_rank == 0.
However in that thread the OP never commented on a solution, and I find myself facing the same issue.
I have tried changing LR/batch size, changing the shuffle and drop_last parameters in the sampler, with or without using the sampler.set_epoch(epoch) method, with or without using the distribute_bn method from timm, different datasets/models, and different number of GPUs (1, 2, and 4, all in a single node using torchrun --nproc_per_node=N train.py). They all have the same problem where the training lags severely behind the single GPU training. Any help or advice would be sincerely appreciated. Thanks in advance.