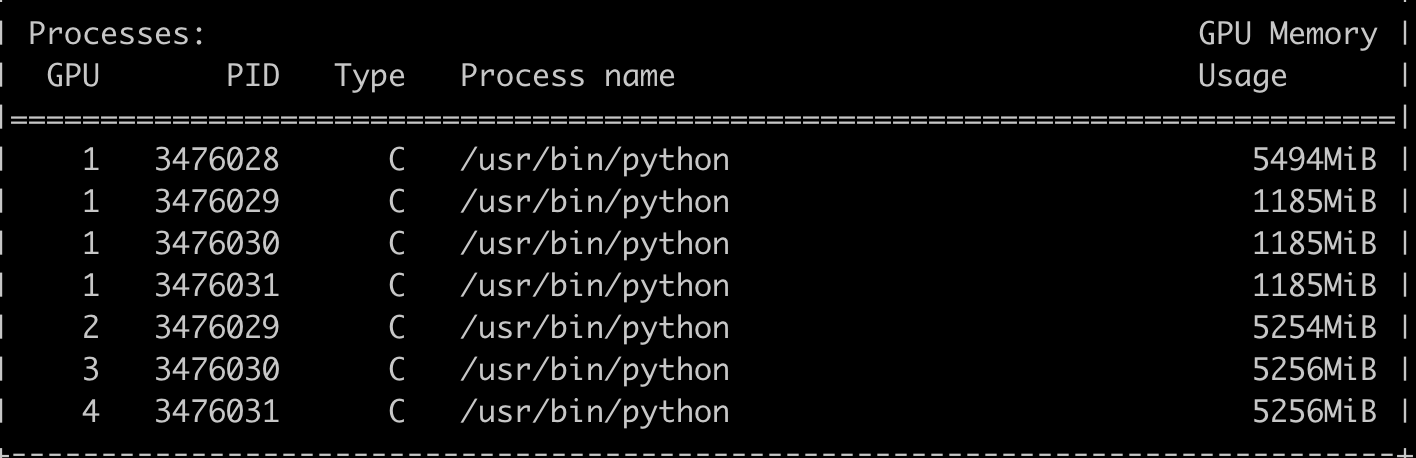
Here’s a screenshot of distributed training in Pytorch when I call the train function like: CUDA_VISIBLE_DEVICES=1,2,3,4 python -m torch.distributed.launch --nproc_per_node=4 train_new.py. You can see that the first rank has also initted 3 separate processes for each other GPU. When I use 10 GPUs on a box this severely limits the batch size, since the 0th dimension node has so much less capacity. What is it storing? I thought gradients in DDP were all-reduced. I’ve also tried turning broadcast_buffers to False to no avail.
Model is stacked modules of 1D-conv, relu, batch norm, LSTM, followed by a large softmax layer and CTC loss. Backend is NCCL
Pytorch 1.3.0, Cuda 10.1, Titan RTX, Ubuntu 18.04. Can provide more code upon request.
This is likely due to some tensors/context is unintentionally created on the 1st GPU, e.g., when calling torch.cuda.empty_cache() without a device guard. Solutions would be either 1) carefully walking though libs/codes to make sure no states leaks to cuda:0, or 2) set CUDA_VISIBLE_DEVICES to let each process only see one GPU.The second approach might be easier.
What @mrshenli mentioned could seamlessly happen when you load saved parameters without specifying map_location. torch.load by default loads parameters to the device where they were, usually the rank 0 device. load_state_dict then copies the loaded value from that device to the target device.
After the intermediate use, torch still occupies the GPU memory as cached memory.
I had a similar issue and solved it by directly loading parameters to the target device.