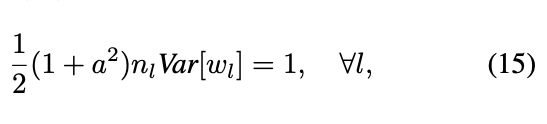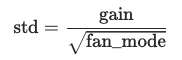Firstly, apologise if these are silly questions!
1 I am wondering what is the default initialisation utilised for Conv layers and is this dependent on the nonlinearity selected for after the layer?
2. When using a SELU nonlinearity, does the network automatically initialise the weights using the LeCun Normal Initialisation? If not, how could I implement weight initialisation manually to use the LeCun Normal?
A bit of context:
Reading through the various blog posts and questions from the past few years, for (1) I managed to find two opposing opinions: either that PyTorch automatically initialises all weights to LeCun Normal, or that PyTorch initialises weights based on the non-linearity used after the Conv Layer (Xavier for Tanh and Kaiming He for ReLU and ReLU derivated). However, when I check the source code (https://github.com/pytorch/pytorch/blob/master/torch/nn/modules/conv.py), it appears that the default weight initlisation is Kaiming:
def reset_parameters(self) -> None:
init.kaiming_uniform_(self.weight, a=math.sqrt(5))
if self.bias is not None:
fan_in, _ = init._calculate_fan_in_and_fan_out(self.weight)
bound = 1 / math.sqrt(fan_in)
init.uniform_(self.bias, -bound, bound)
In this case, my understanding is that that Kaiming is the default weight initialisation for Conv layers, no matter the following nonlinearity? Thus, most of the posts I have previously read are outdated.
Then, in order to implement the LeCun Normal initialisation, do I need to rewrite reset_parameters in my own code so that it overwrites the default PyTorch code?