Hi! I am facing a very strange issue: I have 2 different environments for training NN: (Ubuntu 20.04)
RTX 2070super mobile, CUDA 11.2, pytorch 1.10.0
RTX 3060ti , CUDA 11.4, pytorch 1.10.1
On the first computer, training my NN consumes around 1400MB of GPU ram while the second one uses 2200MB. Their training configs are the same: Its a RL project using PyTorch and stableBaselines. The code is the same. Nonetheless, it still uses more ram from the GPU on the second computer which prevents me from using more parallel training.
I have been advised about pytorch flags. They are the same on both. I wonder if it is an issue with Cuda, PyTorch or a hidden default config of each GPU.
I don’t know how you’ve installed PyTorch but given that you mention CUDA 11.4, I assume you are using source builds.
In this case, the different CUDA versions as well as cuDNN (which versions did you build with?) would most likely have a different memory footprint. If you don’t want to load e.g. the cuDNN kernels and are dynamically linking to it during the build, disable cuDNN via torch.backends.cudnn.enabled=False and check the memory usage again. Also, different GPU generations would load a different amount of kernels in libs such as cuDNN.
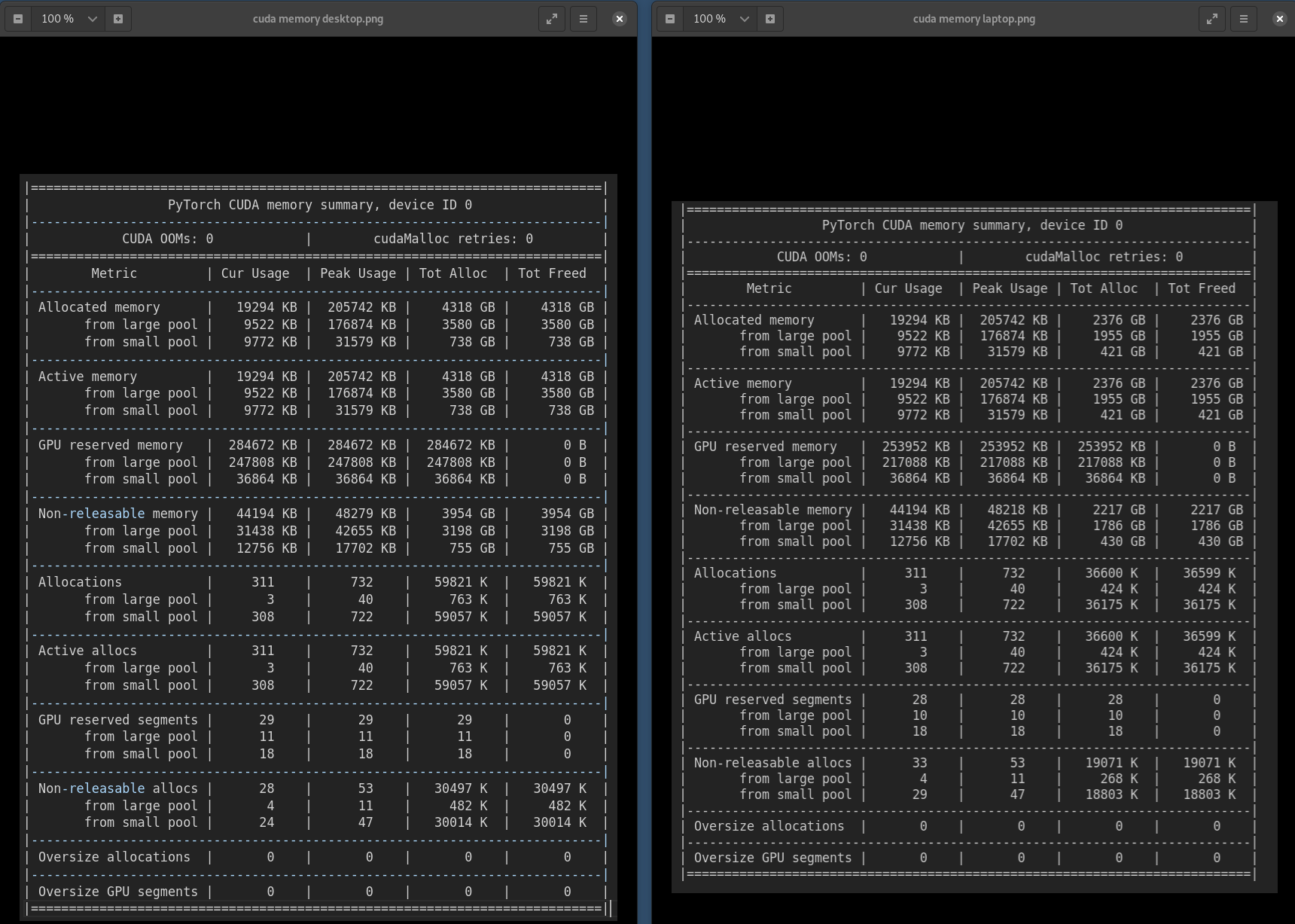
It’s also important what exactly you are measuring since PyTorch uses a caching allocator and can thus reuse memory so you should check the allocated and reserved memory via e.g. torch.cuda.memory_summary().
Thank you for the reply!
disabling cuDNN made just a little difference, around 50MB.
I installed both drivers from the ubuntu official repo, one based on v470(cuda 11.4) and the older using v460(cuda 11.2) from the same source. PyTorch is installed via pip.
Let me share torch.cuda.memory_summary() result from both computers
Since you’ve installed the pip wheels, the tagged CUDA runtime would be used (e.g. 11.3 if selected during the installation) and the local CUDA toolkit would be used if you are building PyTorch from source or a custom CUDA extension.
As can be seen by torch.cuda.memory_summary() the allocated memory is equal (both 19294KB) and the reserved memory (used for the cache) is different. If you don’t want to reuse this memory, clear it via torch.cuda.empty_cache().
After trying different configurations, I can see that the CUDA runtime version and the GPU generation affect the memory usage. I don’t get why both environments consistently use different cache memory allocations.
I am not sure about using that empty_cache() function in the train loop.
Anyway, I can settle with the higher memory usage, as surprisingly the environment with 3 agents perform better than the laptop with 4 (and GPU usage is at 100% on both, no CPU bottleneck)