Hi all ![]()
I’m trying to combine encoder layers output dynamically as below figure :
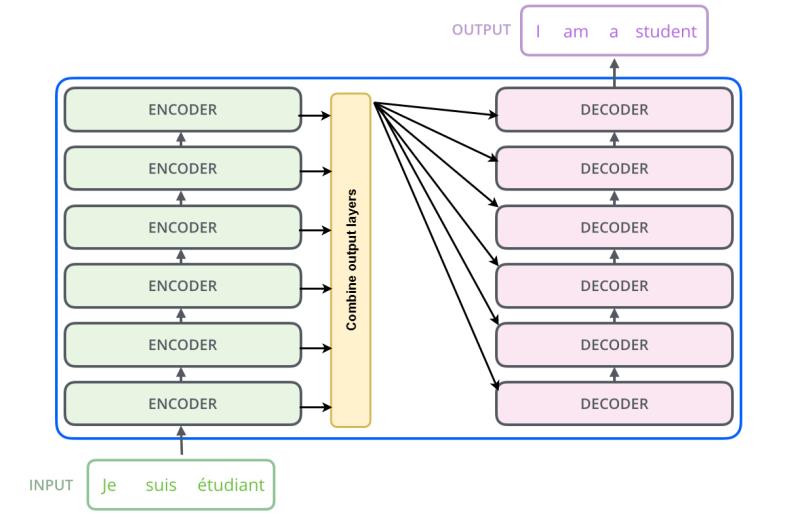
I have followed an answer here using torch.cat(), and my code as below:
#---------------------------------------- Start dynamic combination ----------------------------
for layer in self.layers:
src = layer(src, src_mask)
# I have three layers and I expect 3 vectors
src = torch.cat([src]).view(-1)
src = self.fc_o(src)
#src = [batch size, src len, hid dim]
class Encoder(nn.Module):
def __init__(self,
input_dim,
hid_dim,
n_layers,
n_heads,
pf_dim,
dropout,
device,
max_length = 100):
super().__init__()
self.device = device
self.n_layers = n_layers
self.tok_embedding = nn.Embedding(input_dim, hid_dim)
self.pos_embedding = nn.Embedding(max_length, hid_dim)
self.layers = nn.ModuleList([EncoderLayer(hid_dim,
n_heads,
pf_dim,
dropout,
device)
for _ in range(n_layers)])
self.fc_o = nn.Linear(BATCH_SIZE, input_dim, hid_dim)
self.dropout = nn.Dropout(dropout)
self.scale = torch.sqrt(torch.FloatTensor([hid_dim])).to(device)
#self.fc_o = nn.Linear(BATCH_SIZE, input_dim, hid_dim)
def forward(self, src, src_mask):
#src = [batch size, src len]
#src_mask = [batch size, src len]
batch_size = src.shape[0]
src_len = src.shape[1]
pos = torch.arange(0, src_len).unsqueeze(0).repeat(batch_size, 1).to(self.device)
#pos = [batch size, src len]
src = self.dropout((self.tok_embedding(src) * self.scale) + self.pos_embedding(pos))
#src = [batch size, src len, hid dim]
#---------------------------------------- Start dynamic combination ----------------------------
outputs = []
for layer in self.layers:
outputs.clear()
for layer in self.layers:
src = layer(src, src_mask)
outputs.append(src)
src = torch.cat(outputs, dim=1)
src = self.fc_o(src)
return src
Actually, I’m not sure about my implementation also I got an error:
RuntimeError: size mismatch, m1: [1 x 753664], m2: [256 x 256] at /opt/conda/conda-bld/pytorch_1573049301898/work/aten/src/THC/generic/THCTensorMathBlas.cu:290
Any suggestions to fix this error and to improve the implementation?
Kind regards,
Aiman Solyman
