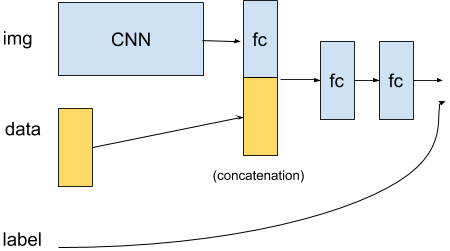
I want to build a CNN model that takes additional input data besides the image at a certain layer.
To do that, I plan to use a standard CNN model, take one of its last FC layers, concatenate it with the additional input data and add FC layers processing both inputs.
The code I need would be something like:
additional_data_dim = 100
output_classes = 2
model = models.__dict__['inception_v3']
del(model._modules['fc'])
# TODO: Concatenate the CNN layer with the additional data
model.fc1 = nn.Linear(2048 + additional_data_dim, 2048 + additional_data_dim)
model.fc2 = nn.Linear(2048 + additional_data_dim, output_classes)
Dim 0 means that you treat the outputs as independent batch samples since you increase the batchsize. However, this is probably not what one would want in this case,since the results of both models belong to the same sample.
Using dim 1 concatenates in each samples channels which makes more sense since they are now belonging to the same sample and this approach can (unlike the first one) even be used if the model’s produce a different number of channels (although the rest of the sizes must be equal)
D:\Softwares\anacond33\lib\site-packages\torch\nn\modules\module.py in call(self, *input, **kwargs)
475 result = self._slow_forward(*input, **kwargs)
476 else:
–> 477 result = self.forward(*input, **kwargs)
478 for hook in self._forward_hooks.values():
479 hook_result = hook(self, input, result)
in forward(self, x, CUDA)
51 print(map2.shape)
52
–> 53 x = torch.cat((map1, map2), dim=1)
54 outputs[i] = x
55
RuntimeError: invalid argument 0: Sizes of tensors must match except in dimension 1. Got 13 and 26 in dimension 2 at c:\programdata\miniconda3\conda-bld\pytorch_1533096106539\work\aten\src\th\generic/THTensorMath.cpp:3616
I am also trying to concatenate two tensors to use as input to a linear layer. Each tensor is the output of a subnetwork that independently processes two input tensors. I am getting the following error:
RuntimeError: Trying to backward through the graph a second time, but the buffers have already been freed. Specify retain_graph=True when calling backward the first time.
I suspect the error has to do with the temporary assignment of a variable to hold the concatenated data x3 = torch.cat((x1, x2), dim=1). The network is defined below:
Thanks for the response. I fixed the typo, and I am still receiving the same error message.
RuntimeError: Trying to backward through the graph a second time, but the buffers have already been freed. Specify retain_graph=True when calling backward the first time.
Here is my training loop:
for epoch in range(5):
running_loss = 0.0
for i, data in enumerate(train_loader, 0):
# get the inputs
inputs, labels = data
energy = inputs[0]
sequence = inputs[1]
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(energy, sequence)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
Yeah, I thought so, since reusing a module shouldn’t throw this error.
I made some assumptions about your code to reproduce the issue. Could you check, if the shapes and criterion are right?
Yes, you are correct. The code you provided does run. I took my training loop and replaced the data coming from the torch.utils.data.DataLoader (train_loader) with a hardcoded random tensor:
for i, data in enumerate(train_loader, 0):
# get the inputs
inputs, labels = data
#energy = inputs[0]
#sequence = inputs[1]
energy = torch.randn(4, 19, 9, 96)
sequence = torch.randn(4, 9, 22)
This eliminates the error message. So, it must have something to do with the way I am getting data out of the DataLoader. Looks like it’s not a problem with the concatenation step!
The problem actually seems to lie in an earlier embedding layer that I used to generate the input data that is fed via the DataLoader:
Thanks for the answers. I have a followup regarding Datasets for these kind of networks.
I have two Data sets I’m working with, one is a time-series and the other is continues and binary data. Each training example has one of each.
I would you recommend building a Dataset that can be used for a network that has concat in it? It seems that all the examples on Datasets work with only one kind of input.
Hi @ptrblck Considering this post of yours, where you can concatenate different nn’s “bodies” before the final layer by using torch.cat(…), may I know what other methods are there available?
It depends on your use case and the provided shapes.
E.g. if both activations have the same shape, you could use a lot of reductions to create a new activation (sum, mean, etc).
The usual way is to create a new activation tensor by concatenating the two previous activations.
Are you looking for a specific method?
I guess @ptrblck I was thinking lstm-ish and the logic of its gates. Does cat-ing and dense-ing different “bodies” does under the hood “gating”? Does min or mean similar shapes “gates” more than what dense-ing does? I guess I find lstm’s, and nn’s in general, fascinating.