I am trying to compute a partial backward with respect to the inputs, and then a second one with respect to the parameters. The easy solution is to do:
However, as I understand, this solution has 2 issues.
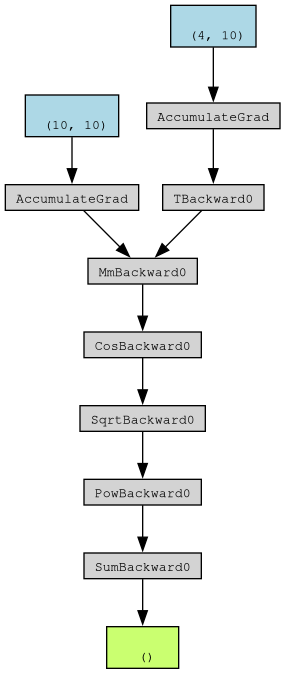
1 - It recomputes all intermediates gradients for the second backward pass. For instance, in this graph, [Sum, Pow, Sqrt, Cos] nodes will be recomputed.
I was able to find a workaround for this using hooks on grad_fn by saving the grads for some nodes and starting the second backward from there. However, doing this still necessitates having retain_graph=True otherwise some necessary saved_tensors are freed. This leads to the second problem,
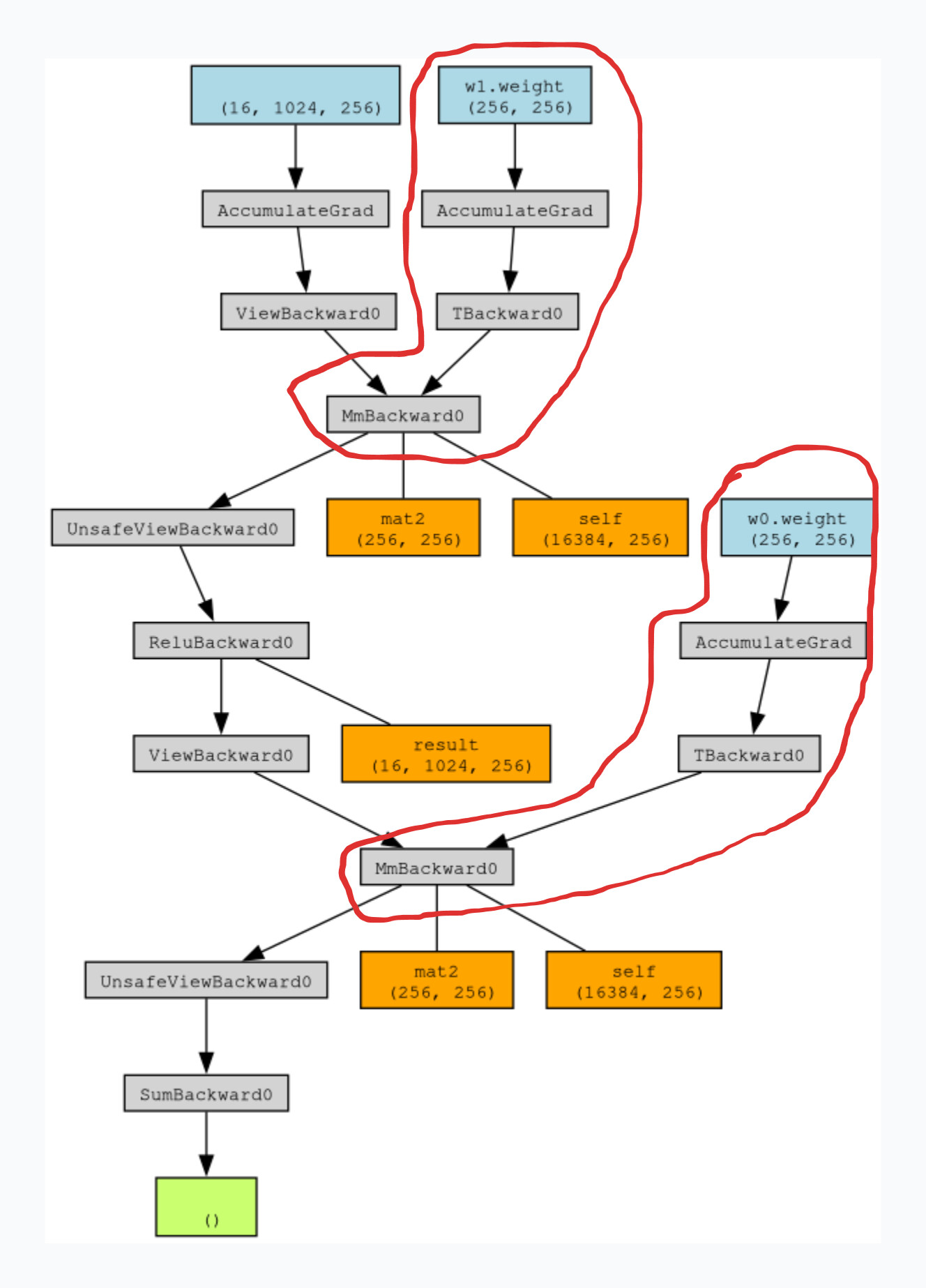
2 - The entire graph and all corresponding saved tensors are kept in memory between the first and second backward pass. In this slightly more complex graph, the only nodes we need to compute the second backward are the ones circled in red, from MmBackward nodes to the weights. The tensor result saved for ReluBackward could be deleted.
On bigger examples the amount of memory saved between the 2 backward passes could be huge, so I would like to know if this is possible. The problem is, since we keep the entire graph and it is not editable from the torch API, there is no way (that I know of) to manually delete some autograd nodes or saved tensors.
Does anyone know if there is a way to partly delete the backward graph while only keeping the nodes we want, with their associated saved tensors?
There’s no way to partially clear a graph in a fine-grained way today, but you can use saved_tensor_hooks Hooks for autograd saved tensors — PyTorch Tutorials 2.6.0+cu124 documentation to manage the saved tensors yourself. When you no longer need the particular saved tensor, you can manually clear it. It requires you to manually define for which nodes you’d like to clear. torch._C._current_autograd_node() which isn’t very easy.
Thanks for your answer. The solution I’m using is to replace layers by a custom autograd node that computes only dy/dx and saves grad_output and x somewhere, then having a separate function to compute dy/dw. The downside is that I need to re-implement dy/dw for every layer, but in my case I only care for Linears so that’s fine
I’m curious what you are using this for by the way. (we’ve been thinking about some of these problems for zero-bubble pipelining, but the we’re building things that are specific to that use case)
For exactly the same problem, zero-bubble pipeline haha
I’m doing some experiments on distributed training and I needed to have an implementation of this. I looked at torch pipelining’s way of handling it but it seems a bit odd
Since you keep some nodes for the stage_backward_weight call, aren’t all nodes kept between the 2 calls due to the graph structure? There are still some references to the other nodes, which have references to their saved tensors. And because the backward is called with retain_graph=True, they’re not deleted by autograd. Is there something I’m missing?
x = torch.randn(batch_size, seq_len, dim, device = device)
target = torch.randn(batch_size, seq_len, dim, device = device)
with Measure("forward"):
loss = F.mse_loss(model(x), target)
with Measure("backward input"):
dinputs, param_groups = stage_backward_input([loss], None, [x], model.parameters())
with Measure("backward parameters"):
wgrads = stage_backward_weight(model.parameters(), param_groups)
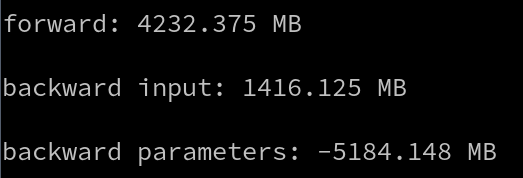
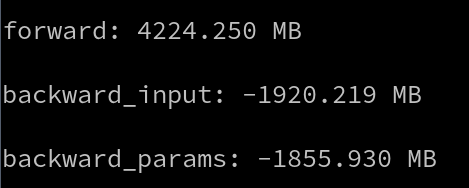
Running that small example on a Transformer model gives this, where memory does not seem freed after stage_backward_inputs
(Measure prints the memory difference after the computation)
So, maybe I got something wrong on how those functions work? They showed here that they measured the memory reduction during training, but I’m wondering what was the model used
You’re not missing too much I think haha - Yes, I’d expect the peak memory to be higher than what is theoretically possible due to retains_graph=True on the entire graph.
But in my head, part of why this isn’t so bad is because (1 )the first stage was previously (1F1B) the bottleneck on peak activation memory and this change does not make the peak memory on the first stage worse and (2) its most impactful on the last stage but all this does is just bring the peak memory of the last stage close to the first stage.
Yes that’s true, it’s not that important for zero-bubble schedules since the first stage is the bottleneck. It only matters when the peak on the last device is higher somehow
Thanks again for the information. If you ever implement a generic way to do that in autograd I’d be interested in using it!