with Howard Huang, Will Constable, Ke Wen, Jeffrey Wan, Haoci Zhang, Dong Li, Weiwei Chu
TL;DR
In this post, we’ll dive into a few key innovations in torch.distributed.pipelining that make it easier to apply pipeline parallelism, including zero-bubble schedules, to your models. And we’ll highlight an end to end example of training LLMs with torch.distributed.pipelining composed together with FSDP and Tensor Parallelism in TorchTitan, and share learnings that helped improve composability and clean up the model.
- Support for manual model partitioning or compiler-based graph splitting
- Declarative schedule format (IR) decouples schedule writing from executor implementation, and provides a library of schedule generators.
- Autograd support for automatic zero-bubble avoids the need for a custom autograd.function and manually partitioned backwards
Distributed with TorchTitan Series
The GitHub repository TorchTitan is a proof of concept for large-scale LLM training using native PyTorch, designed to be easy to understand, use, and extend for different training purposes, supporting multi-dimensional parallelisms with modular components. In this series of topics, we introduce the latest PyTorch features for distributed training enabled in Torchtitan.
- Topic 1: Enabling Float8 All-Gather in FSDP2
- Topic 2: Introducing Async Tensor Parallelism in PyTorch
- Topic 3: Optimizing Checkpointing Efficiency with PyTorch DCP
- → Topic 4: Training with Zero-Bubble Pipeline Parallelism
Introducing Pipeline Parallelism in PyTorch
Pipeline Parallelism is notoriously difficult to apply to a model, and also more bottlenecked by bubble overhead, compared to data parallelism. However, recently with the invention of the zero-bubble schedule, pipeline parallelism is more competitive, and it’s an important ingredient for large scale training (and for distributed inference as well).
torch.distributed.pipelining APIs make it easier to apply pipeline parallelism to your model and experiment with new schedule formats. For more detailed API documentation, see our docs page. For more usage guidelines, see our tutorial and TorchTitan.
Model Partitioning, Schedule Definition, and Execution
Pipeline parallelism in PyTorch is built upon three fundamental abstractions: model partitioning, schedule definition, and execution. These are embodied in the classes of PipelineStage, which handles model partitioning, PipelineSchedule which defines the schedule based on a configuration of stage counts, ranks, or microbatches, and PipelineScheduleRuntime which manages execution.
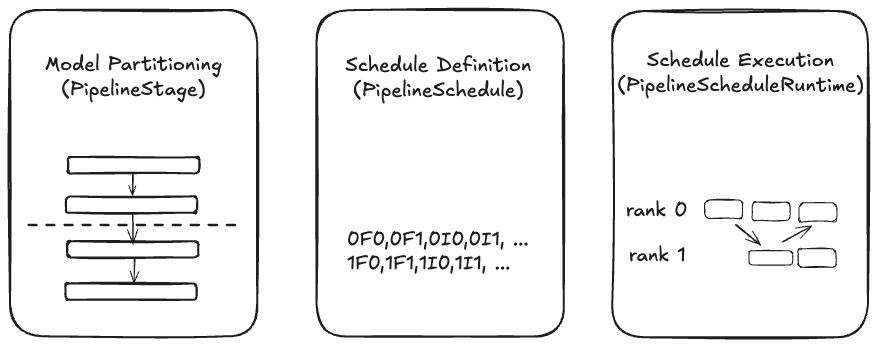
PipelineStage provides methods for shape inference, ensuring that the dimensions of tensors are correctly determined as they traverse through different stages. When these stages communicate, the tensor shapes they exchange are contingent upon the input microbatch’s shape. During execution, stages engage in metadata exchange to guarantee the precise transfer of data, accompanied by validation of expected shapes. This process is crucial to prevent any potential hangs, as it ensures that all stages are in agreement regarding tensor shapes.
PipelineStage also offers the flexibility of both manual and automatic splitting. Users can manually partition models using an nn.Module class-based wrapper, or they can opt for compiler-based splitting through torch.export. This dual approach empowers users with greater adaptability, enabling them to develop utility functions that can partition a model in various ways to suit their specific needs. Compiler-based splitting, while simpler for some users, can be harder to compose with other parallelisms, so we generally recommend manual splitting.
The pipeline stage abstraction was chosen to more easily integrate with the execution engine; however, this integration is not mandatory. The components of our solution are designed to be orthogonal, allowing them to be adopted independently. This modularity means that while we provide a comprehensive execution engine for pipeline schedules, users are free to utilize our schedule intermediate representation (IR) to craft their own execution strategies, bypassing our API constructs if desired. Details about the IR are covered in the next section.
Schedule Authoring via IR
One of the challenges of implementing or prototyping a new pipeline schedule is that it’s tricky to write send/recv communications in a correct way in SPMD-style code. Concretely, pipeline schedules tend to involve lots of loops and conditionals for deciding which action to issue, and also require send/recv operations to be well overlapped, which can result in code that’s fragile and can lead to hangs that are difficult to debug. That’s why we introduced a new IR-based schedule format, allowing you to break the schedule writing process down as illustrated in the following example for a trivial zero-bubble style schedule:
- Generate a simple “compute only” schedule trace for each rank (programmatically). Here,
1F0means run stage 1’s 0th microbatch Forward operation. Stages are globally numbered.
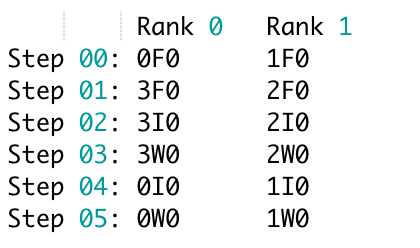
- Apply compiler passes to insert communication operations where needed and overlap them
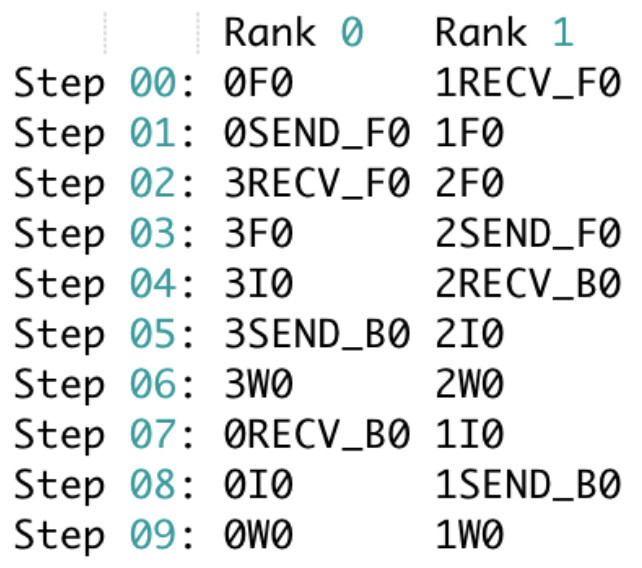
- Execute the IR on an execution backend
These steps are all easy to inspect and test, since the IR is serializable to CSV format or can be printed or rendered in chrometrace. That also means that if you want to make a small tweak to your schedule to see how it behaves, you’re free to directly edit the trace and run it without first figuring out how to update your generator code.
We also provide tools to simulate the execution of the IR just for correctness (to flush out potential ordering issues or invalid schedules) before finally executing on hardware. During development, these tools helped quickly identify bugs.
The IR format is also easy to extend- for example, we have exploratory work integrating with FSDP’s zero-3 where IR is used to signal the unshard and reshard operations for data parallelism.
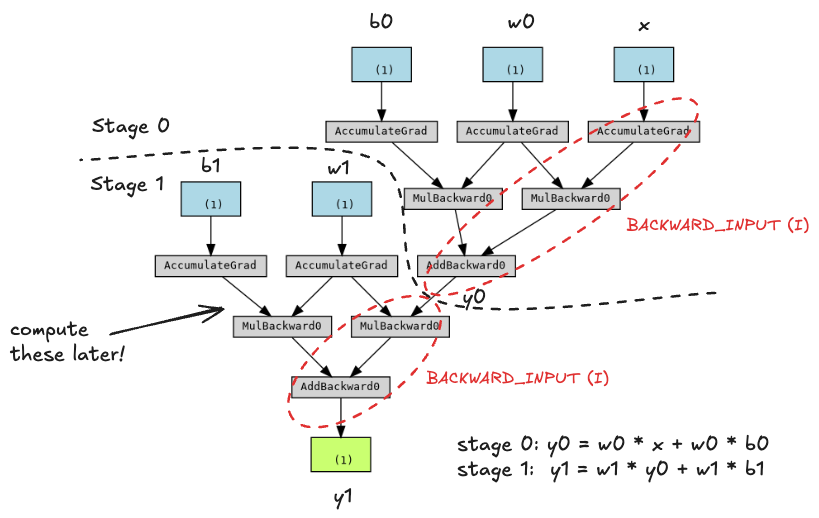
You may also notice that there are separate operations in the IR for ‘FULL_BACKWARD’ (B) and ‘BACKWARD_INPUT’ (I) / ‘BACKWARD_WEIGHT’ (W). This allows for generating schedules like the zero-bubble schedule, but in order to actually execute these schedules, you’ll need a way to separate these components out of the ‘backward pass’. That’s why torch.distributed.pipelining adds support for automated backwards partitioning.
Autograd Support for Zero Bubble
The zero-bubble paper’s key insight was recognizing that only part of the backward pass, which computes input gradients, is on the critical path to the next pipeline stage. The rest, which computes weight gradients, can be computed separately to fill in pipeline bubbles.
In order to run a zero-bubble schedule, you need to first partition the backward operation. In the original zero-bubble work, this is done manually which can be difficult (example), but may be preferred by some users. To support manual cases, we introduce stage_backward_input and stage_backward_weight methods. For other users who want more of the simplicity of pytorch and autograd, we developed an automatic partitioning feature.
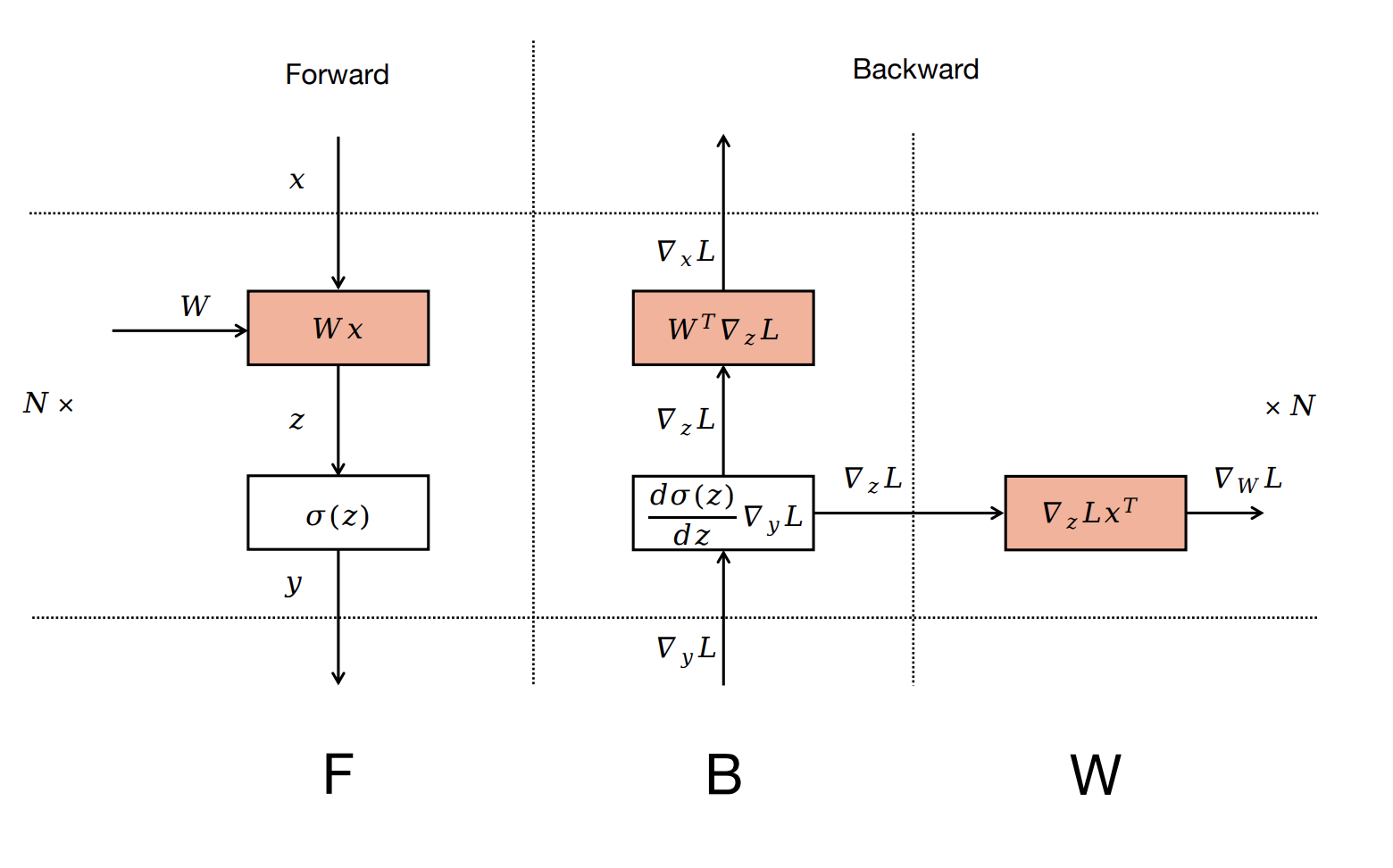
Most PyTorch users are familiar with the concept of writing only the forward pass and getting the backward pass for free. This is made possible by the Autograd system, which captures a graph of backward operations as forward is run. By simply traversing and partitioning this graph, we can automatically generate functions for computing the input gradient and weight gradient of a particular pipeline stage. Critically, we save shared values used by the weight gradient computation so they do not need to be recomputed.
Additionally, we have verified that memory usage is correctly released as the schedule is executed, as illustrated in the memory profile below:
To allow better modularity, users can opt to use automatic partitioning if they want, or write their own backward or weight grad update function. They can register their custom weight grad update function to be called during execution.
Currently torch.compile and zero-bubble are not compatible, but we are exploring how to enable them to work together.
Learnings from TorchTitan
Setting up the Pipeline-Friendly Training Loop
One challenge we faced when pipelining torchtitan was keeping train.py clean while accommodating the changes needed for pipeline parallelism. When pipelining, there can be multiple (virtual) stages per pipeline rank, each represented by one nn.Module and having its own Optimizer and LR scheduler. We found it was possible to refactor the training loop code in several ways to make pipelining changes easier, and minimize the number of branches or duplicate codepaths for pipeline vs non-pipeline execution. The key changes we landed on are summarized below:
- Keep a list of ‘model chunks’ and ‘optimizers’, rather than single objects, helping unify the checkpointer calls
- Apply ‘SPMD parallelisms’ and torch.compile inside a ‘per-model-chunk’ helper
- Factor the loss function as a helper that can be used inside the pipeline executor or called in the non-pipelined train loop
Changes Inside the Model
To make manual partitioning smooth, we introduced a couple of changes to the model code:
- Switching .layers from an nn.ModuleList to nn.ModuleDict made it so that fully-qualified-names (FQNs) did not change after partitioning, which ensured smooth checkpointing
- Writing model.forward() in a way that tolerated ‘None’ layers let us partition simply by deleting unused layers from a full model copy for each stage. (e.g. Stage 1+ deletes the input embedding, and .forward() code handles this transparently).
Model Initialization and RNG Configuration
Model initialization is another area that needs to be changed for pipelining. The two key changes were (1) updating init_weights to be pipeline-stage friendly, and (2) configuring the RNG properly for pipelining.
Torchtitan uses meta-device initialization since it avoids initializing ‘the whole model’ on one device, which is critical for larger models that can’t fit in device memory. To implement meta initialization, you must write an ‘init_weights’ function that can be called after the model is sharded and materialized. For init_weights compatibility, we just needed to make sure it tolerated the missing layers which we deleted when applying pipelining.
To ensure that initialization results in unique values per stage, we must configure RNG seeds appropriately. Since torchtitan uses DTensor based SPMD parallelisms, we mainly need to ensure that each SPMD world starts out with one shared RNG seed, because DTensor manages RNG offsets itself to ensure different initialization of different model shards. With pipeline parallelism, we need one unique seed per pipeline rank, since each pipeline rank corresponds to a ‘SPMD world’.
Conclusion
To demonstrate the composability of PP with that native Pytorch distributed APIs, we ran experiments on TorchTitan on a LLaMa3 405B model using 3D parallelism (FSDP + TP + PP). We also combined this with new techniques such as torch.compile, Async TP and Float8 Allgather and ran various job sizes ranging from 8 GPUs to 512 GPUs. We include the data of these runs in the TorchTitan paper and show a select few below:
| GPUs | Schedule | Memory | Words per second (WPS) |
|---|---|---|---|
| 256 | 1F1B | 87.20GiB | 103 |
| 256 | Interleaved 1F1B | 89.53GiB | 109 |
| 512 | 1F1B | 65.79GiB | 96 |
| 512 | Interleaved 1F1B | 68.44GiB | 124 |
| 512 | ZeroBubble (without compile) | 82.86GiB | 125 |
In summary, we hope our work on torch.distributed.pipelining makes pipeline parallelism more accessible and efficient for large-model training and inference. By leveraging features such as model partitioning, a declarative schedule format, and automated backwards partitioning, we are able to provide a wide range of complex schedules as defaults to the user. The integration with TorchTitan further enhances the composability of different parallelism strategies, providing a robust example for production settings. As we look to the future, ongoing work will focus on automatic optimizations in the schedule runtime, hardening the IR format, and upstreaming different schedules. We welcome any contributions and suggestions from the community on this work.