For exactly the same problem, zero-bubble pipeline haha
I’m doing some experiments on distributed training and I needed to have an implementation of this. I looked at torch pipelining’s way of handling it but it seems a bit odd
Since you keep some nodes for the stage_backward_weight call, aren’t all nodes kept between the 2 calls due to the graph structure? There are still some references to the other nodes, which have references to their saved tensors. And because the backward is called with retain_graph=True, they’re not deleted by autograd. Is there something I’m missing?
x = torch.randn(batch_size, seq_len, dim, device = device)
target = torch.randn(batch_size, seq_len, dim, device = device)
with Measure("forward"):
loss = F.mse_loss(model(x), target)
with Measure("backward input"):
dinputs, param_groups = stage_backward_input([loss], None, [x], model.parameters())
with Measure("backward parameters"):
wgrads = stage_backward_weight(model.parameters(), param_groups)
Running that small example on a Transformer model gives this, where memory does not seem freed after stage_backward_inputs
(Measure prints the memory difference after the computation)
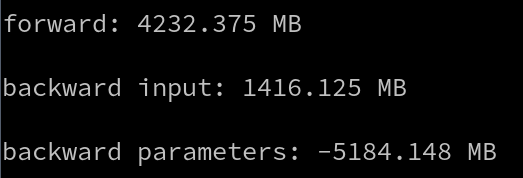
On the same model, using my implementation, I was able to get this:
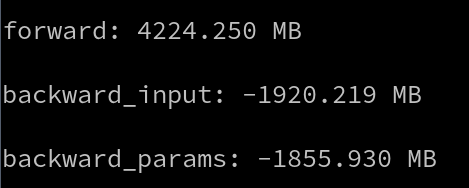
So, maybe I got something wrong on how those functions work? They showed here that they measured the memory reduction during training, but I’m wondering what was the model used