My goal is to train a CNN where the initial FC layer is concatenated with additional data as described here:
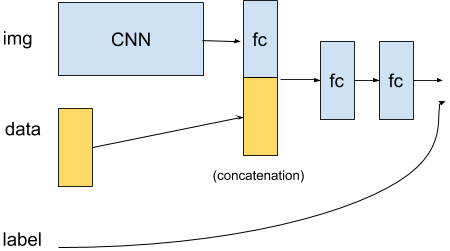
Source:
https://discuss.pytorch.org/t/concatenate-layer-output-with-additional-input-data/20462?u=yui_88
I was able to build such a model with a vgg16 base.
class MyModel(nn.Module):
def __init__(self, model, data_dim, n_classes=4, input_size=(3, 224, 224)):
super(MyModel, self).__init__()
self.n_classes = n_classes
self.input_size = input_size
self.data_dim = data_dim
# Convert fc layers to conv layers
self.features = model.features
self.classifier = model.classifier
self.concat_data()
# Freeze conv weights
for p in self.features.parameters():
p.requires_grad = False
def forward(self, image, data):
x1 = self.features(image)
x1 = torch.flatten(x1, 1)
x2 = data
x = torch.cat((x1, x2), dim=1)
x = self.classifier(x)
return x
def concat_data(self):
num_features = self.classifier[0].in_features + self.data_dim
first_layer = nn.Linear(num_features, self.classifier[0].out_features)
num_features = self.classifier[6].in_features
features = [first_layer] + list(self.classifier.children())[1:-1]
features.extend([nn.Linear(num_features, 4)])
self.classifier = nn.Sequential(*features)
And here is what my model looks like
MyModel(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(classifier): Sequential(
(0): Linear(in_features=25096, out_features=4096, bias=True)
(1): ReLU(inplace)
(2): Dropout(p=0.5)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace)
(5): Dropout(p=0.5)
(6): Linear(in_features=4096, out_features=4, bias=True)
)
)
when I check the gradients after the backpropagating the loss in backward() using print(model.fc1.weight.grad), the loss starts at 1.38 and eventually becomes nan. The gradients also become nan after a few iterations.
Could this possibly be due to vanishing gradients? If so, how can I possibly fix it given that I’already using Relu activation function?