Hi Guys,
Posted a query some days ago regarding memory issues I ran into during classification: Memory Issues while Classifying Images I think I’ve been able to fix it but ran into another issue.
Here’s my code:
num_classes = 8
learning_rate = 1e-3
batch_size = 4
num_epochs = 50
mean=[0.5, 0.5, 0.5]
std=[0.5, 0.5, 0.5]
train_transforms = transforms.Compose([transforms.Resize((104, 104)),
transforms.ToTensor(),
transforms.Normalize(torch.Tensor(mean), torch.Tensor(std))])
valid_transforms = transforms.Compose([transforms.Resize((104, 104)),
transforms.ToTensor(),
transforms.Normalize(torch.Tensor(mean), torch.Tensor(std))])
train_set = torchvision.datasets.ImageFolder(root=train_path,
transform=train_transforms
)
valid_set = torchvision.datasets.ImageFolder(root=valid_path,
transform=valid_transforms
)
train_dataset = DataLoader(train_set,
batch_size=batch_size,
shuffle=True)
valid_dataset = DataLoader(valid_set,
batch_size=batch_size,
shuffle=False)
images = images.cuda()
labels = torch.tensor(labels)
labels = labels.cuda()
model = nn.Sequential()
# 1st Convolution Layer
model.add_module('conv1',
nn.Conv2d(in_channels=3,
out_channels=32,
kernel_size=3,
stride=1,
padding=1))
model.add_module('relu1', nn.ReLU())
model.add_module('pool1',nn.MaxPool2d(kernel_size=2))
# 2nd Convolution Layer
model.add_module('conv2',
nn.Conv2d(in_channels=32,
out_channels=64,
kernel_size=3,
stride=1,
padding=1))
model.add_module('relu2', nn.ReLU())
model.add_module('pool2', nn.MaxPool2d(kernel_size=2))
# 3rd Convolution Layer
model.add_module('conv3',
nn.Conv2d(in_channels=64,
out_channels=128,
kernel_size=3,
stride=1,
padding=1))
model.add_module('relu3', nn.ReLU())
model.add_module('pool3', nn.MaxPool2d(kernel_size=2))
model.add_module('flatten', nn.Flatten())
### Fully Connected Layer
model.add_module('fc1', nn.Linear(21294, 15000))
model.add_module('relu4', nn.ReLU())
model.add_module('dropout1', nn.Dropout(p=0.5))
model.add_module('fc2', nn.Linear(15000, 8000))
model.add_module('relu5', nn.ReLU())
model.add_module('dropout2', nn.Dropout(p=0.5))
model.add_module('fc3', nn.Linear(8000, 3000))
model.add_module('relu6', nn.ReLU())
model.add_module('dropout3', nn.Dropout(p=0.5))
model.add_module('fc4', nn.Linear(3000, num_classes))
model = model.to(device)
loss_func = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
# Train the Model:
def train(model, num_epochs, train_dl, valid_dl):
loss_hist_train = [0]*num_epochs
accuracy_hist_train = [0]*num_epochs
loss_hist_valid = [0]*num_epochs
accuracy_hist_valid = [0]*num_epochs
for epoch in range(num_epochs):
model.train()
for x_batch, y_batch in train_dl:
pred = model(x_batch)
loss = loss_func(pred, y_batch)
loss.backward()
optimizer.step()
optimizer.zero_grad()
loss_hist_train[epoch] += loss.item()*y_batch.size(0)
is_correct = (torch.argmax(pred, dim=1)==y_batch).float()
accuracy_hist_train[epoch] += is_correct.sum()
loss_hist_train[epoch] /= len(train_dl.dataset)
accuracy_hist_train[epoch] /= len(train_dl.dataset)
model.eval()
with torch.no_grad():
for x_batch, y_batch in valid_dl:
pred = model(x_batch)
loss = loss_func(pred, y_batch)
loss_hist_valid[epoch] += loss.item()*y_batch.size(0)
is_correct = (torch.argmax(pred, dim=1)==y_batch).float()
accuracy_hist_valid[epoch] += is_correct.sum()
loss_hist_valid[epoch] /= len(valid_dl.dataset)
accuracy_hist_valid[epoch] /= len(valid_dl.dataset)
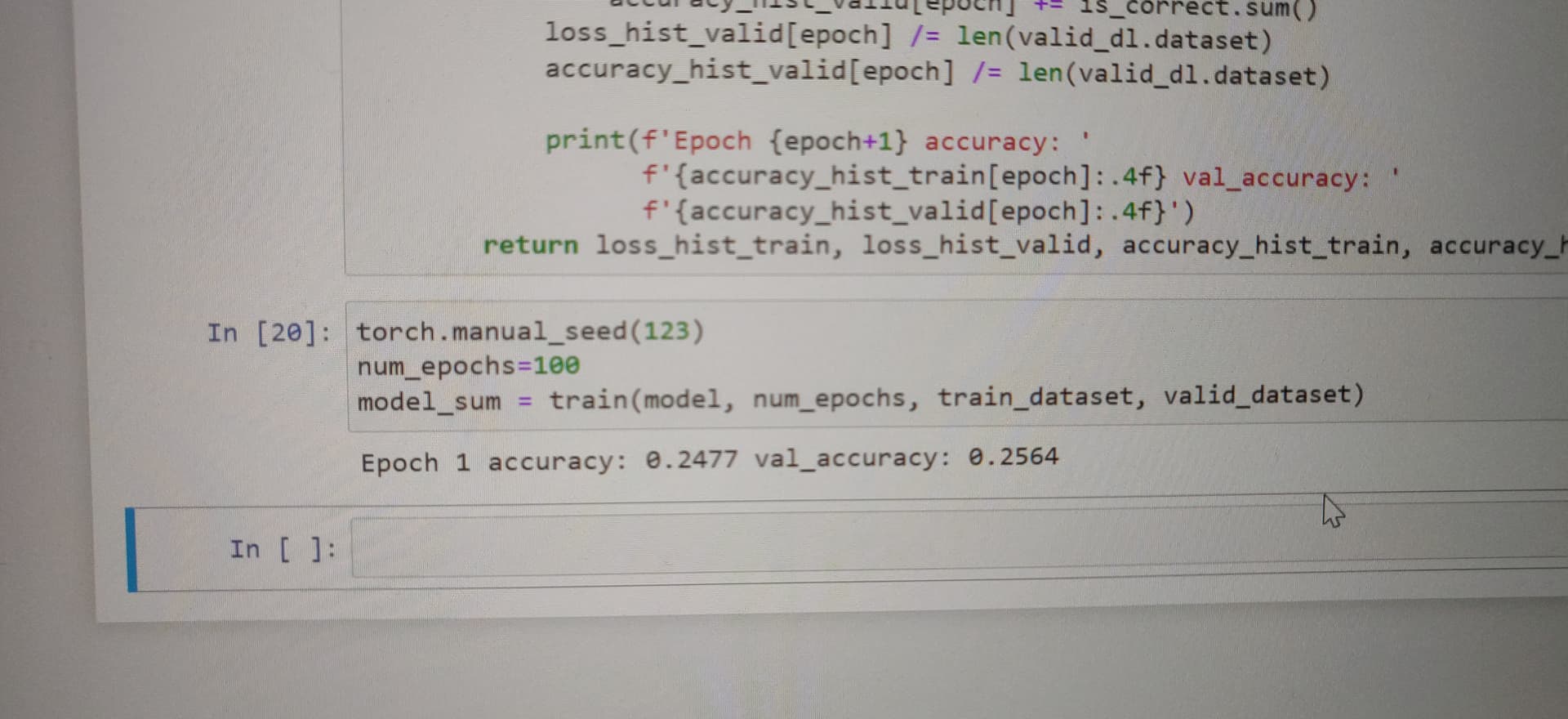
print(f'Epoch {epoch+1} accuracy: '
f'{accuracy_hist_train[epoch]:.4f} val_accuracy: '
f'{accuracy_hist_valid[epoch]:.4f}')
return loss_hist_train, loss_hist_valid, accuracy_hist_train, accuracy_hist_valid
torch.manual_seed(123)
model_sum = train(model, num_epochs, train_dataset, valid_dataset)
Here’s my error:
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
Input In [114], in <cell line: 3>()
1 torch.manual_seed(123)
2 num_epochs=50
----> 3 model_sum = train(model, num_epochs, train_dataset, valid_dataset)
Input In [113], in train(model, num_epochs, train_dl, valid_dl)
10 model.train()
11 for x_batch, y_batch in train_dl:
---> 12 pred = model(x_batch)
13 loss = loss_func(pred, y_batch)
14 loss.backward()
File ~\anaconda3\envs\myai\lib\site-packages\torch\nn\modules\module.py:1130, in Module._call_impl(self, *input, **kwargs)
1126 # If we don't have any hooks, we want to skip the rest of the logic in
1127 # this function, and just call forward.
1128 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1129 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1130 return forward_call(*input, **kwargs)
1131 # Do not call functions when jit is used
1132 full_backward_hooks, non_full_backward_hooks = [], []
File ~\anaconda3\envs\myai\lib\site-packages\torch\nn\modules\container.py:139, in Sequential.forward(self, input)
137 def forward(self, input):
138 for module in self:
--> 139 input = module(input)
140 return input
File ~\anaconda3\envs\myai\lib\site-packages\torch\nn\modules\module.py:1130, in Module._call_impl(self, *input, **kwargs)
1126 # If we don't have any hooks, we want to skip the rest of the logic in
1127 # this function, and just call forward.
1128 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1129 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1130 return forward_call(*input, **kwargs)
1131 # Do not call functions when jit is used
1132 full_backward_hooks, non_full_backward_hooks = [], []
File ~\anaconda3\envs\myai\lib\site-packages\torch\nn\modules\conv.py:457, in Conv2d.forward(self, input)
456 def forward(self, input: Tensor) -> Tensor:
--> 457 return self._conv_forward(input, self.weight, self.bias)
File ~\anaconda3\envs\myai\lib\site-packages\torch\nn\modules\conv.py:453, in Conv2d._conv_forward(self, input, weight, bias)
449 if self.padding_mode != 'zeros':
450 return F.conv2d(F.pad(input, self._reversed_padding_repeated_twice, mode=self.padding_mode),
451 weight, bias, self.stride,
452 _pair(0), self.dilation, self.groups)
--> 453 return F.conv2d(input, weight, bias, self.stride,
454 self.padding, self.dilation, self.groups)
RuntimeError: Input type (torch.FloatTensor) and weight type (torch.cuda.FloatTensor) should be the same or input should be a MKLDNN tensor and weight is a dense tensor