Hi guys,
I am new to CNN and Pytorch, I tried to classify Micro-organisms on Pytorch and ran into memory errors. My system is windows 64bits, 16gb ram, 512gb SSD, 1tb HDD and GTX 3060x 6GB GDDR6 dedicated Graphics card
I am training a model to classify microorganisms with 8 labels, here’s a summary of my code:
num_classes = 8
learning_rate = 1e-3
batch_size = 8
num_epochs = 50
train_transforms = transforms.Compose([transforms.Resize((240, 240)),
transforms.ToTensor(),
transforms.Normalize(torch.Tensor(mean), torch.Tensor(std))])
valid_transforms = transforms.Compose([transforms.Resize((240, 240)),
transforms.ToTensor(),
transforms.Normalize(torch.Tensor(mean), torch.Tensor(std))])
train_set = torchvision.datasets.ImageFolder(root=train_path,
transform=train_transforms
)
valid_set = torchvision.datasets.ImageFolder(root=valid_path,
transform=valid_transforms
)
train_dataset = DataLoader(train_set,
batch_size=batch_size,
shuffle=True)
valid_dataset = DataLoader(valid_set,
batch_size=batch_size,
shuffle=False)
model = nn.Sequential()
# 1st Convolution Layer
model.add_module('conv1',
nn.Conv2d(in_channels=3,
out_channels=32,
kernel_size=3,
stride=1,
padding=1))
model.add_module('relu1', nn.ReLU())
model.add_module('pool1',nn.MaxPool2d(kernel_size=2))
# 2nd Convolution Layer
model.add_module('conv2',
nn.Conv2d(in_channels=32,
out_channels=64,
kernel_size=3,
stride=1,
padding=1))
model.add_module('relu2', nn.ReLU())
model.add_module('pool2', nn.MaxPool2d(kernel_size=2))
# 3rd Convolution Layer
model.add_module('conv3',
nn.Conv2d(in_channels=64,
out_channels=128,
kernel_size=3,
stride=1,
padding=1))
model.add_module('relu3', nn.ReLU())
model.add_module('pool3', nn.MaxPool2d(kernel_size=2))
### Flatten output from the last layer
model.add_module('flatten', nn.Flatten())
### Fully Connected Layer
model.add_module('fc1', nn.Linear(115200, 20000))
model.add_module('relu4', nn.ReLU())
model.add_module('dropout1', nn.Dropout(p=0.5))
model.add_module('fc2', nn.Linear(20000, 10000))
model.add_module('relu5', nn.ReLU())
model.add_module('dropout2', nn.Dropout(p=0.5))
model.add_module('fc3', nn.Linear(10000, 5000))
model.add_module('relu6', nn.ReLU())
model.add_module('dropout3', nn.Dropout(p=0.5))
model.add_module('fc4', nn.Linear(5000, num_classes))
loss_func = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
### Training Model
def train(model, num_epochs, train_dl, valid_dl):
loss_hist_train = [0]*num_epochs
accuracy_hist_train = [0]*num_epochs
loss_hist_valid = [0]*num_epochs
accuracy_hist_valid = [0]*num_epochs
for epoch in range(num_epochs):
model.train()
for x_batch, y_batch in train_dl:
pred = model(x_batch)
loss = loss_func(pred, y_batch)
loss.backward()
optimizer.step()
optimizer.zero_grad()
loss_hist_train[epoch] += loss.item()*y_batch.size(0)
is_correct = (torch.argmax(pred, dim=1)==y_batch).float()
accuracy_hist_train[epoch] += is_correct.sum()
loss_hist_train[epoch] /= len(train_dl.dataset)
accuracy_hist_train[epoch] /= len(train_dl.dataset)
model.eval()
with torch.no_grad():
for x_batch, y_batch in valid_dl:
pred = model(x_batch)
loss = loss_func(pred, y_batch)
loss_hist_valid[epoch] += loss.item()*y_batch.size(0)
is_correct = (torch.argmax(pred, dim=1)==y_batch).float()
accuracy_hist_valid[epoch] += is_correct.sum()
loss_hist_valid[epoch] /= len(valid_dl.dataset)
accuracy_hist_valid[epoch] /= len(valid_dl.dataset)
print(f'Epoch {epoch+1} accuracy: '
f'{accuracy_hist_train[epoch]:.4f} val_accuracy: '
f'{accuracy_hist_valid[epoch]:.4f}')
return loss_hist_train, loss_hist_valid, accuracy_hist_train, accuracy_hist_valid
torch.manual_seed(123)
num_epochs=100
model_sum = train(model, num_epochs, train_dataset, valid_dataset)
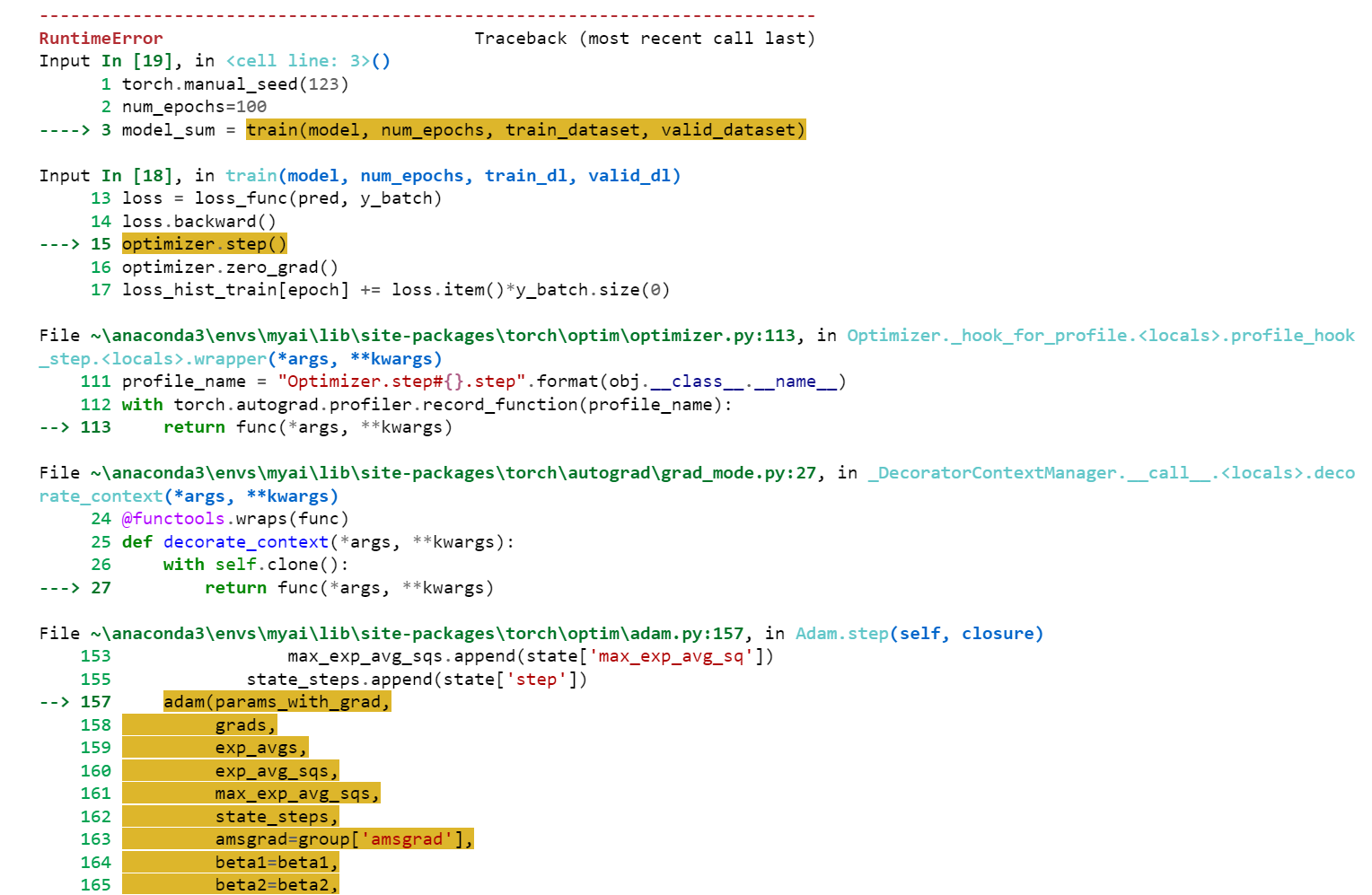
Here is my error:
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
Input In [19], in <cell line: 3>()
1 torch.manual_seed(123)
2 num_epochs=100
----> 3 model_sum = train(model, num_epochs, train_dataset, valid_dataset)
Input In [18], in train(model, num_epochs, train_dl, valid_dl)
13 loss = loss_func(pred, y_batch)
14 loss.backward()
---> 15 optimizer.step()
16 optimizer.zero_grad()
17 loss_hist_train[epoch] += loss.item()*y_batch.size(0)
File ~\anaconda3\envs\myai\lib\site-packages\torch\optim\optimizer.py:113, in Optimizer._hook_for_profile.<locals>.profile_hook_step.<locals>.wrapper(*args, **kwargs)
111 profile_name = "Optimizer.step#{}.step".format(obj.__class__.__name__)
112 with torch.autograd.profiler.record_function(profile_name):
--> 113 return func(*args, **kwargs)
File ~\anaconda3\envs\myai\lib\site-packages\torch\autograd\grad_mode.py:27, in _DecoratorContextManager.__call__.<locals>.decorate_context(*args, **kwargs)
24 @functools.wraps(func)
25 def decorate_context(*args, **kwargs):
26 with self.clone():
---> 27 return func(*args, **kwargs)
File ~\anaconda3\envs\myai\lib\site-packages\torch\optim\adam.py:157, in Adam.step(self, closure)
153 max_exp_avg_sqs.append(state['max_exp_avg_sq'])
155 state_steps.append(state['step'])
--> 157 adam(params_with_grad,
158 grads,
159 exp_avgs,
160 exp_avg_sqs,
161 max_exp_avg_sqs,
162 state_steps,
163 amsgrad=group['amsgrad'],
164 beta1=beta1,
165 beta2=beta2,
166 lr=group['lr'],
167 weight_decay=group['weight_decay'],
168 eps=group['eps'],
169 maximize=group['maximize'],
170 foreach=group['foreach'],
171 capturable=group['capturable'])
173 return loss
File ~\anaconda3\envs\myai\lib\site-packages\torch\optim\adam.py:213, in adam(params, grads, exp_avgs, exp_avg_sqs, max_exp_avg_sqs, state_steps, foreach, capturable, amsgrad, beta1, beta2, lr, weight_decay, eps, maximize)
210 else:
211 func = _single_tensor_adam
--> 213 func(params,
214 grads,
215 exp_avgs,
216 exp_avg_sqs,
217 max_exp_avg_sqs,
218 state_steps,
219 amsgrad=amsgrad,
220 beta1=beta1,
221 beta2=beta2,
222 lr=lr,
223 weight_decay=weight_decay,
224 eps=eps,
225 maximize=maximize,
226 capturable=capturable)
File ~\anaconda3\envs\myai\lib\site-packages\torch\optim\adam.py:305, in _single_tensor_adam(params, grads, exp_avgs, exp_avg_sqs, max_exp_avg_sqs, state_steps, amsgrad, beta1, beta2, lr, weight_decay, eps, maximize, capturable)
303 denom = (max_exp_avg_sqs[i].sqrt() / bias_correction2_sqrt).add_(eps)
304 else:
--> 305 denom = (exp_avg_sq.sqrt() / bias_correction2_sqrt).add_(eps)
307 param.addcdiv_(exp_avg, denom, value=-step_size)
RuntimeError: [enforce fail at C:\cb\pytorch_1000000000000\work\c10\core\impl\alloc_cpu.cpp:81] data. DefaultCPUAllocator: not enough memory: you tried to allocate 9216000000 bytes.