I have a segmentation network which looks like this. I preTrain(forward pass has preTrain=True) it on the on the VOC dataset. But during pretraining only the last layer conv1_1_2 has gradient flowing and the weights getting updated. I have put the network class and gradient flow plot below.
class Network(nn.Module):
def __init__(self, num_classes):
super().__init__()
# pre-trained features
backbone = vgg16(is_caffe=True)
l7 = [('fc7', nn.Conv2d(512, 1, 1))]
l8 = [('fc8', nn.Conv2d(3, 3, 1))]
self.encoder = copy.deepcopy(backbone)
self.conv1_1_1=nn.Sequential(OrderedDict(l7))
self.conv1_1_2=nn.Sequential(OrderedDict(l8))
def forward(self, x, weights,preTrain=True):
x = self.encoder(x)
x=x/x.max()
if preTrain==False:
# weights come another network branch only in main training
suppQueryFusion = [torch.add(x,weight.repeat(1, 1, x.size(2), x.size(3))) for weight in weights]
else:
suppQueryFusion = [x for weight in weights]
weightedFeats = [self.conv1_1_1(feat) for feat in suppQueryFusion]
concatedFeats = torch.cat( weightedFeats,dim=1)
normClassFeats=F.normalize(concatedFeats,p=2,dim=1)
Fusion=self.conv1_1_2(normClassFeats)
x=self.conv1_1_2(Fusion)
return x
The method for getting the plot can be seen [Check gradient flow in network - #7 by RoshanRane].
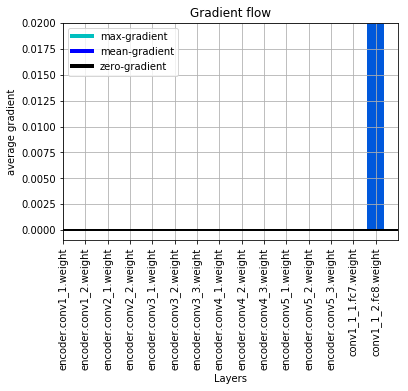
Could someone guide me why the gradient flow is zero and how I could overcome it?