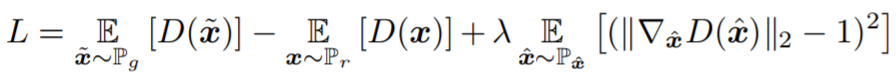I would like to use the gradient penalty introduced in the NIPS paper https://arxiv.org/abs/1706.04156 . In the paper, whenever updating the generator, the gradient penalty for the discriminator parameters is considered.
I know there is a discussion in the previous post (https://discuss.pytorch.org/t/how-to-implement-gradient-penalty-in-pytorch/1656?u=zhangboknight , where the gradient penalty is calculated with respect to the data points
For my case the gradient penalty is calculated with respect to the discriminator parameters:
The authors of the paper gives an implementation through tf.gradients(V, discriminator_vars) in tensorflow (https://github.com/locuslab/gradient_regularized_gan/blob/c1f61272f6176d4d13016779dbe730b346ae21a1/gaussian-toy-regularized.py#L112 )
Is there a similar implementation in Pytorch? Can I still use torch.autograd.grad to calculate the gradient wrt. discriminator params? Or can I use .retain_grad() as suggested in https://discuss.pytorch.org/t/how-do-i-calculate-the-gradients-of-a-non-leaf-variable-w-r-t-to-a-loss-function/5112/2?u=zhangboknight ? I am not pretty sure. Since this technique helps stabilize the GAN training greatly, the same problem may help others who use Pytorch. Many thanks!
chenyuntc
January 7, 2018, 11:42am
2
I think autograd.grad with create_graph=True would work for you.
2 Likes
Thanks a lot! Now I can calculate the norm of gradient through:grad_params = torch.autograd.grad(loss, model.parameters(), create_graph=True)grad_norm = 0for grad in grad_params:grad_norm += grad.pow(2).sum()grad_norm = grad_norm.sqrt()
Another reference is the post: https://discuss.pytorch.org/t/hessian-vector-product-with-create-graph-flag/8357?u=zhangboknight and https://discuss.pytorch.org/t/issues-computing-hessian-vector-product/2709/7?u=zhangboknight
2 Likes
tom
January 7, 2018, 9:11pm
4
Hello Tony,
thanks for highlighting the paper!
I put my pytorch version of the experiment in a quick Regularized gradient descent GAN optimization notebook . The core is very similar to what you and Yun Chen came up with.
I do have a specific problem in mind where I will try it on. Thanks again for bringing this up here.
Best regards
Thomas
2 Likes
psu1
March 27, 2019, 2:13am
5
from torch.autograd import grad
preds = Critic(interpolates)
gradients = grad(outputs=preds, inputs=interpolates,
grad_outputs=torch.ones_like(preds).cuda(),
retain_graph=True, create_graph=True, only_inputs=True)[0]
gradients = gradients.view(gradients.size(0), -1)
gradient_norm = gradients.norm(2, dim=1)
gradient_penalty = ((gradient_norm - 1)**2).mean()
2 Likes